Actowiz Metrics Real-time  analytics dashboard for brands! Try Free Demo
analytics dashboard for brands! Try Free Demo
Scalable web, app & AI-powered extraction. 99.9% accuracy.
All Services → Core Scraping Services
Core Scraping Services
 Top Global Platforms
Top Global Platforms
 Platforms by Region
Platforms by Region
🇦🇪 Expanding across UAE, Saudi, Qatar, Kuwait & more
Request Custom Platform →🌏 Singapore, Indonesia, Thailand, Philippines, Vietnam & Malaysia
Request Custom Platform →🌎 Brazil, Mexico, Argentina, Colombia & Chile
Request Custom Platform → Pricing & Promotions
Pricing & Promotions
 Brand & Intelligence
Brand & Intelligence
 Digital Shelf & Search
Digital Shelf & Search
 Assortment
Assortment For Retailers
For RetailersWhich solution fits?
Talk to Expert Marketplace Scrapers
Marketplace Scrapers
 Data APIs
Data APIs Universal APIs
Universal APIs Delivery & SDKs
Delivery & SDKsReady to integrate?
Start Free Trial Knowledge Center
Knowledge Center
 Guides & Playbooks
Guides & Playbooks
 Downloads & Tools
Downloads & Tools
 Trust & Company
Trust & CompanyScalable web, app & AI-powered extraction. 99.9% accuracy.
All Services → Core Scraping Services
Top Global Platforms
Pricing & Promotions
Brand & Intelligence
Digital Shelf & Search
Assortment For RetailersWhich solution fits?
Talk to Expert Marketplace Scrapers
Data APIs Universal APIs Delivery & SDKsReady to integrate?
Start Free Trial Knowledge Center
Guides & Playbooks
Downloads & Tools
Trust & Company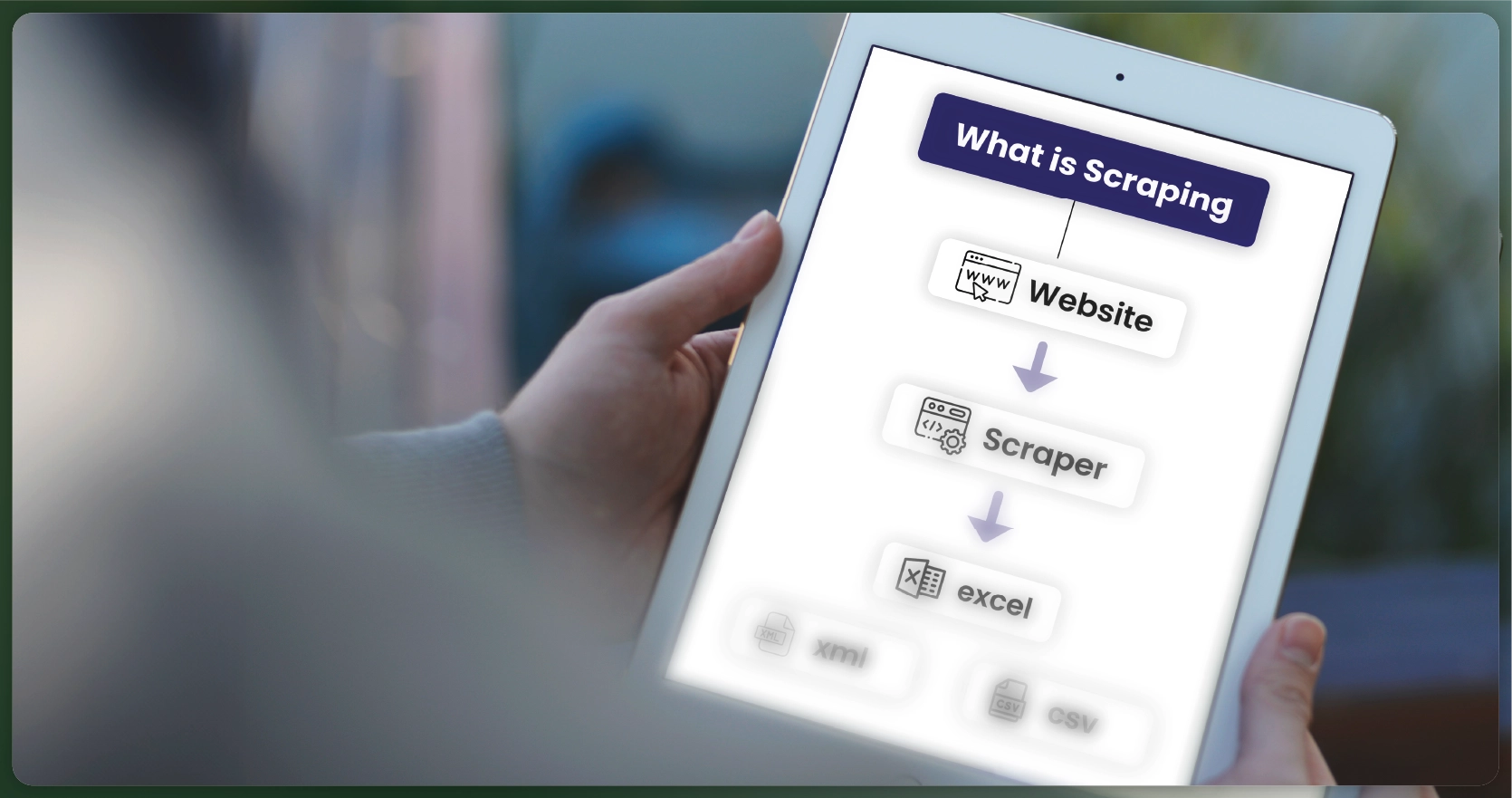
Scraping, often referred to as web scraping or data extraction, involves the automated collection of data from websites. It plays a crucial role in data mining by extracting valuable information from web pages and converting it into structured formats for analysis.
Web scraping technologies include various tools and techniques designed to simplify the extraction process. Web scraping APIs and data scrapers are commonly used to automate data collection, making it efficient to scrape data from websites. These tools help in automated data collection, allowing businesses to gather large datasets quickly.
API integration is a method that enables seamless data retrieval from web services, while web scraping datasets provide structured data for analysis. Scraping also offers significant data mining benefits by uncovering insights from unstructured data across the web.
Advantages of web scraping include the ability to monitor competitors, analyze market trends, and gather customer feedback. It's valuable for enterprise web scraping data, enhancing decision- making processes. Additionally, mobile app scraping extends these capabilities to app data, ensuring a comprehensive data collection approach.

Data scraping: technologies are essential tools for extracting information from websites and online sources. These technologies vary in complexity and functionality, catering to different data extraction needs. Here’s an overview of the primary types:
Web Scraping Tools: These are specialized software programs designed to extract data from websites. They work by parsing HTML and XML documents to gather information. Popular tools include BeautifulSoup and Scrapy, which simplify the process of navigating and extracting data from web pages.
Web Scraping APIs: APIs (Application Programming Interfaces) offer a structured way to access data from web services. Web scraping APIs provide a standardized interface for retrieving data, making it easier to integrate with other applications.
Browser Extensions: These tools integrate directly with web browsers, enabling users to scrape data from web pages while browsing. Extensions like Web Scraper for Chrome allow users to define extraction rules and automate data collection without needing separate software.
Custom Scripts: Custom scripts, often written in languages like Python, provide a flexible and tailored approach to data scraping. Using libraries such as Selenium or Puppeteer, developers can create scripts that interact with web pages, handle dynamic content, and manage complex scraping scenarios.
Automated Bots: Bots are software agents that mimic human interactions with web pages. They can automate repetitive tasks, such as filling out forms or navigating through multiple pages. Bots are particularly useful for scraping data from sites that require user interaction.
Data Scraping Frameworks:Comprehensive frameworks like Scrapy and BeautifulSoup offer robust solutions for building custom scraping applications. These frameworks include tools for managing requests, parsing responses, and handling data storage.
Each technology has its advantages and is chosen based on the complexity of the scraping task, the type of data needed, and the website’s structure. Understanding these options helps in selecting the most suitable tool for effective data extraction.
APIs (Application Programming Interfaces) and manual data scraping are two distinct approaches to extracting data from websites. Each has its own set of advantages and limitations, which can influence the choice of method based on specific needs and objectives.
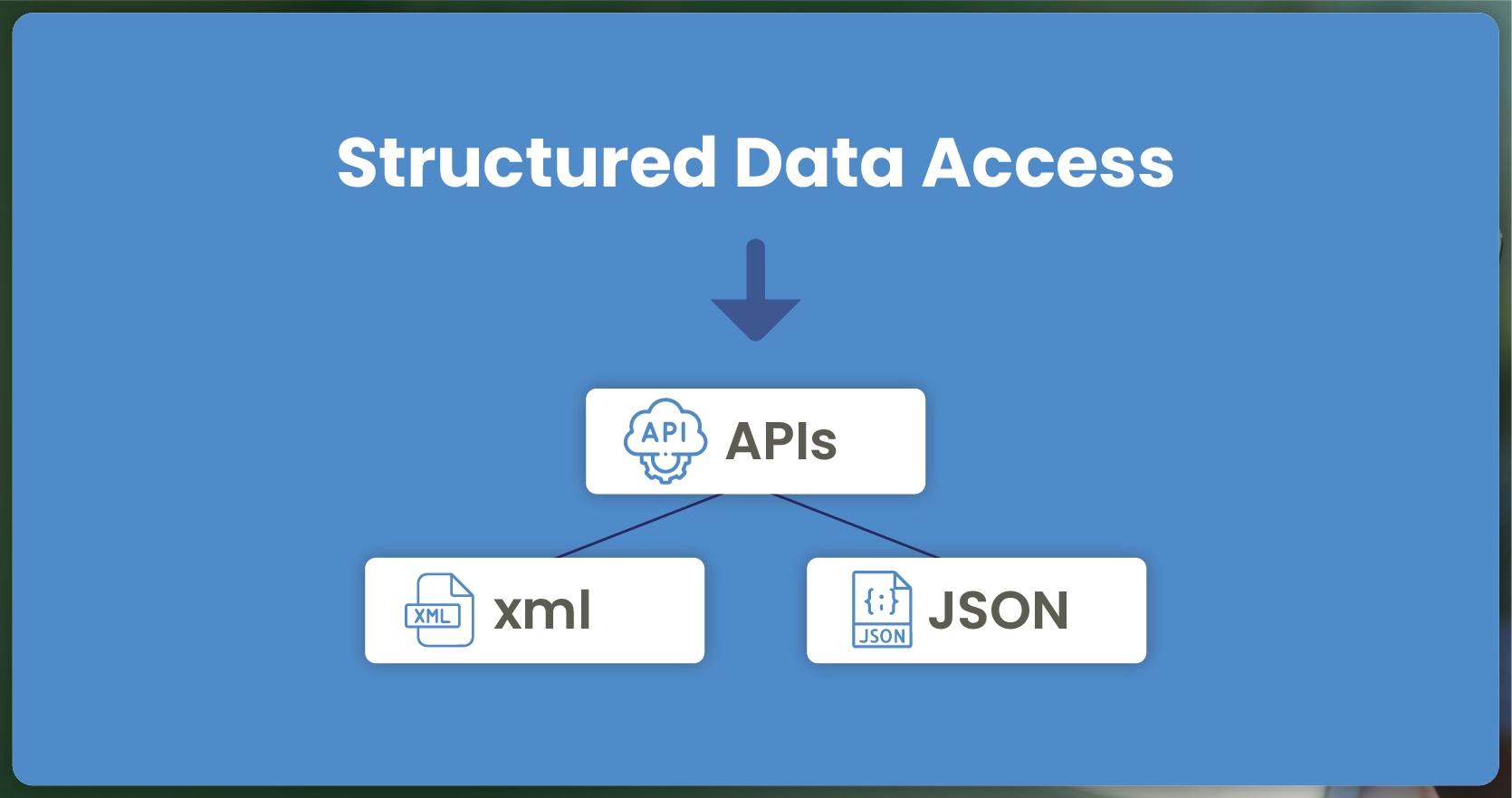
Advantages:
Structured Data Access: APIs provide data in a structured format, such as JSON or XML, making it easier to integrate into applications or databases. This eliminates the need for additional parsing and processing.
Reliability: APIs are designed to provide consistent data access. As long as the API is available and functional, you can rely on its stability.
Efficiency: APIs typically offer higher efficiency by providing direct access to data without the need for web scraping tools. This can significantly reduce the time and resources required for data collection.
Compliance: Using APIs often ensures compliance with the website’s terms of service, as many sites provide APIs specifically for data access.
Disadvantages:
Limited Data: APIs may not expose all the data available on a website, restricting the scope of data you can access.
Rate Limits: Many APIs impose rate limits to prevent abuse, which can restrict the volume of data you can retrieve within a given timeframe.
Cost: Some APIs, especially those offering extensive data, may come with usage fees, making them less economical for large-scale data extraction.
Advantages:
Flexibility: Manual scraping allows for the extraction of any visible data from web pages, regardless of the availability of an API. This flexibility can be crucial for gathering data not provided through APIs.
Comprehensive Data Collection: Manual scraping can access all types of data presented on a website, including complex and dynamic content that might not be available through APIs.
Disadvantages:
Complexity: Manual scraping often requires custom code and handling of website structure changes. It can be more complex to implement and maintain compared to using APIs.
Ethical and Legal Risks: Scraping websites manually can sometimes violate terms of service or legal restrictions, potentially leading to legal issues or IP bans.
Resource-Intensive: Manual scraping can be resource-intensive, requiring significant computing power and time to process and extract data from multiple pages.
Choosing between APIs and manual scraping depends on factors such as the availability of APIs, the scope of data needed, and legal considerations. Understanding these pros and cons can help determine the most suitable method for effective data extraction.

Efficient data scraping is essential for obtaining accurate and valuable insights while minimizing the risk of encountering technical issues or legal challenges. Adhering to best practices can ensure successful data extraction and streamlined automated data collection. Here are some key strategies for effective data scraping:
Define Clear Objectives: Before starting a web scraping project, clearly outline your goals and the specific data you need. This helps in choosing the right tools and methods for data extraction. Understanding your requirements will also guide you in setting up an efficient web scraper.
Choose the Right Tools: Select appropriate web scraping tools based on the complexity of the task. For simpler needs, lightweight tools or web scrapers may suffice, while more complex tasks might require advanced frameworks or API integration.
Utilize API Integration: Whenever possible, use API integration for data extraction. APIs often provide a more structured and reliable data source compared to scraping, reducing the need for complex parsing and handling. APIs can simplify data collection and ensure better compliance with data access policies.
Implement Rate Limiting: Respect the target website's rate limits to avoid overloading their servers and potentially getting banned. Implementing rate limiting in your scraping process helps maintain a good relationship with data sources and prevents disruptions.
Handle Data Responsibly: Ensure that the data collected is used responsibly and ethically. Adhere to privacy regulations and the website's terms of service. Proper data handling practices are essential to maintain credibility and avoid legal complications.
Monitor and Adapt: Regularly monitor your scraping processes and be prepared to adapt to changes in website structures or data formats. This ensures that your data extraction remains accurate and reliable over time.
Optimize Data Storage:Efficiently store and manage the extracted data using appropriate databases or data formats. Proper data organization facilitates easy access and analysis, enhancing the overall efficiency of your data scraping efforts.
Test and Validate: Thoroughly test your web scraper to ensure it accurately extracts the desired data. Validate the results against known data points to confirm the reliability and accuracy of the scraping process.
By following these best practices, you can optimize your data scraping efforts, streamline automated data collection, and achieve more effective data extraction. Whether you're utilizing API integration or traditional scraping methods, ensuring efficiency and accuracy is key to leveraging data for actionable insights.

Data scraping, the process of extracting information from websites, is a powerful tool for acquiring valuable insights. However, it operates within a complex legal framework that varies by jurisdiction and context. Understanding the legal landscape is crucial to ensure compliance and avoid potential legal issues.
1. Website Terms of Service: Most websites have terms of service that outline acceptable usage policies. These terms often prohibit unauthorized data extraction. Violating these terms can lead to legal consequences, such as cease-and-desist orders or legal action. Always review and adhere to a website’s terms of service before scraping.
2. Intellectual Property Rights: The data on websites may be protected by intellectual property laws, including copyrights and trademarks. Scraping content that is copyrighted or trademarked without permission can infringe on these rights. It’s important to distinguish between publicly available data and content protected by intellectual property laws.
3. Data Privacy Regulations: Data scraping must comply with data privacy regulations, such as the GDPR (General Data Protection Regulation) in the EU or the CCPA (California Consumer Privacy Act) in the US. These laws regulate how personal data is collected, stored, and used. Scraping personal data without consent can lead to significant legal penalties.
4. Anti-Scraping Technologies: Many websites deploy anti-scraping technologies, such as CAPTCHAs or IP bans, to prevent unauthorized data extraction. Circumventing these technologies can be considered a violation of the Computer Fraud and Abuse Act (CFAA) in the US or similar laws in other jurisdictions.
5. Case Law: Court decisions, such as those involving scraping cases like hiQ Labs, Inc. v. LinkedIn Corp., illustrate the legal complexities of data scraping. These cases highlight the balance between data access and proprietary rights, influencing how scraping activities are judged in legal contexts.
6. Ethical Considerations: Beyond legality, ethical considerations play a role in data scraping. Responsible scraping practices involve transparency, respecting user privacy, and ensuring that data collection aligns with ethical standards.
Navigating the legal landscape of data scraping requires a careful approach to comply with regulations and respect intellectual property and privacy rights. Staying informed about legal developments and adopting responsible scraping practices can help mitigate risks and ensure lawful data collection.

Data scraping has become a pivotal tool across various industries, enabling organizations to gather insights, enhance decision-making, and gain a competitive edge. By extracting valuable information from websites, businesses can leverage data scraping to address specific needs and challenges in their respective fields. Here’s how data scraping is applied across different industries:
1. E-Commerce: In the e-commerce sector, data scraping is used to monitor competitors’ pricing, track product availability, and analyze market trends. Retailers can extract data on competitor prices and inventory levels to adjust their own pricing strategies and optimize product offerings. This helps maintain competitive pricing and enhance product positioning.
2. Finance: Financial institutions use data scraping to gather information from financial news sites, stock market platforms, and economic reports. By scraping news and market data, financial analysts can identify trends, perform sentiment analysis, and make informed investment decisions. This helps in tracking market movements and assessing investment opportunities.
3. Travel and Hospitality: Travel agencies and hotel operators leverage data scraping to collect information on flight prices, hotel rates, and customer reviews. By analyzing this data, they can adjust pricing, improve customer service, and offer personalized travel recommendations. Scraping helps in understanding market dynamics and enhancing customer satisfaction.
4. Real Estate: In real estate, data scraping is used to gather property listings, market prices, and demographic data. Real estate professionals can analyze trends, assess property values, and identify investment opportunities. This data helps in making informed decisions and understanding local market conditions.
5. Healthcare: Healthcare providers use data scraping to extract information from medical journals, research papers, and patient reviews. This helps in tracking medical advancements, analyzing treatment outcomes, and improving patient care. Data scraping supports evidence- based practices and research in the healthcare sector.
6. Job Market: Recruitment agencies and job boards scrape job listings, salary information, and employer reviews. This data helps in understanding job market trends, analyzing salary ranges, and improving recruitment strategies. It aids in matching job seekers with suitable opportunities and assessing industry demands.
7. News and Media: Media organizations scrape news sites and social media platforms to gather information on trending topics and public sentiment. This data supports content creation, audience engagement, and competitive analysis. It helps in delivering timely and relevant news content to audiences.
Data scraping’s versatility across industries underscores its importance in acquiring actionable insights and staying competitive. By leveraging this technology, organizations can drive innovation, optimize operations, and enhance their strategic decisions.
In the world of data scraping, various tools and technologies are available, each offering unique capabilities and benefits. Choosing the right tool depends on factors like the complexity of the scraping task, the volume of data required, and the technical expertise available. This comparative analysis will explore some popular scraping tools and technologies, highlighting their strengths and potential limitations.

Beautiful Soup:
Strengths: Beautiful Soup is a Python library that allows users to parse HTML and XML documents, making it ideal for beginners. It’s highly flexible and integrates well with other Python libraries like Requests and Pandas.
Limitations: It may not be suitable for large-scale scraping projects due to its relatively slower performance compared to other libraries.
Scrapy:
Strengths: Scrapy is an open-source Python framework designed for large-scale web scraping tasks. It’s highly efficient and can handle multiple pages and large datasets, making it a preferred choice for complex projects.
Limitations: Requires more technical knowledge to set up and use, which might be a barrier for non-developers.
Selenium:
Strengths: Selenium automates web browsers, allowing users to scrape data from dynamic websites that rely heavily on JavaScript. It mimics human interaction with web pages, making it powerful for scraping content rendered by JavaScript.
Limitations: Slower compared to other tools as it involves real-time browser interaction. It also requires significant setup and maintenance.
Puppeteer:
Strengths: Puppeteer, a Node.js library, enables you to control headless Chrome or Chromium browsers through a powerful API. It’s particularly useful for scraping dynamic content and for testing web applications.
Limitations: Limited to the Chrome browser environment and requires knowledge of JavaScript.

When engaging in web scraping, one of the most common challenges faced is dealing with IP bans and captchas. These measures are implemented by websites to protect their data from being accessed too frequently or by unauthorized bots. However, there are strategies and best practices that can help you overcome these hurdles while ensuring that your scraping activities remain ethical and efficient.
Why It Matters: Many websites monitor the frequency and volume of requests coming from a single IP address. If too many requests are made in a short period, the site may block the IP, preventing further access.
Solution: Use IP rotation services or proxies to distribute requests across multiple IP addresses. This method reduces the likelihood of triggering IP bans by simulating requests from different users. Tools like Bright Data or Smartproxy can help manage this process effectively.
Why It Matters: Rapid-fire requests can flag your activities as bot-like behavior, leading to IP bans or captcha triggers.
Solution: Introduce time delays between requests, varying the intervals to mimic human browsing patterns. By randomizing the time between requests, you can reduce the risk of detection. Using tools like Scrapy’s AutoThrottle extension can automate this process.
Why It Matters: Captchas are designed to differentiate between human users and bots. Encountering captchas can halt your scraping process.
Solution: There are two main approaches to solving captchas: manual intervention or automated captcha-solving services like 2Captcha or Anti-Captcha. For less critical scraping, consider integrating these services into your scraper to bypass captchas automatically.
Why It Matters: If your scraping patterns are too predictable, they can be easily detected by anti-scraping measures.
Solution: Vary your request headers, user-agent strings, and other identifiable characteristics. Tools like Fake User-Agent libraries can generate random user-agent strings to disguise your scraper’s identity.
Why It Matters: Ignoring a site’s robots.txt file or its terms of service can not only result in IP bans but also legal consequences.
Solution: Always check the robots.txt file before scraping a website. Adhere to the rules specified to avoid scraping disallowed sections and stay within legal boundaries.

As data scraping becomes increasingly popular, it's crucial to address the ethical implications associated with this practice. Data scraping involves extracting information from websites and online platforms, which can raise concerns about privacy, intellectual property, and fair use. Understanding and adhering to ethical standards is essential to ensure that your data scraping activities are both responsible and legally sound.
Respecting Personal Data: One of the primary ethical considerations in data scraping is the handling of personal data. Websites often contain sensitive information such as names, email addresses, and other personal details. Scraping this data without consent can violate privacy laws, including regulations like the General Data Protection Regulation (GDPR) in Europe and the California Consumer Privacy Act (CCPA) in the U.S.
Ethical Approach: Always consider whether the data you are scraping includes personal information. If it does, ensure you have explicit consent to collect and use this data. In cases where consent is not possible, anonymize the data to protect individual privacy.
Respecting Copyright and Ownership: Websites often contain content that is protected by copyright, including text, images, and videos. Scraping copyrighted material without permission can lead to legal issues, including claims of intellectual property infringement.
Ethical Approach: Limit your scraping activities to data that is publicly available and clearly not subject to copyright restrictions. When using scraped data, consider the purpose—whether it falls under the doctrine of fair use, which typically allows for commentary, criticism, or educational purposes.
Respecting Website Policies: Many websites outline their data usage policies in their terms of service (ToS) or robots.txt file. Ignoring these guidelines can lead to legal repercussions and harm your reputation.
Ethical Approach: Always review and comply with a website's ToS before scraping. If the ToS prohibits scraping, it’s important to seek alternative methods of obtaining data or to request permission from the site owner.
Being Transparent: Ethical data scraping involves transparency in how data is collected and used. Clearly communicate the purpose of data collection and how it will be utilized, especially if the data will be shared or sold.
Ethical Approach: Maintain accountability by documenting your data scraping practices, including the methods used, the data collected, and how it is stored and protected. This transparency builds trust with users and stakeholders.

As technology continues to evolve, data scraping and automation are becoming increasingly sophisticated, shaping the way businesses collect and utilize data. The future of data scraping is set to be influenced by several emerging trends that promise to enhance efficiency, accuracy, and scalability.
Advanced Machine Learning Algorithms: Artificial intelligence (AI) and machine learning (ML) are transforming data scraping by enabling more intelligent and adaptive scraping techniques. These technologies can automatically adjust scraping strategies in response to changes in website structures, reducing the need for manual intervention.
Natural Language Processing (NLP): NLP is being used to better understand and extract valuable information from unstructured data, such as customer reviews or social media posts. This allows businesses to gain deeper insights from textual data sources.
Increased Use of Cloud-Based Scraping Solutions: Cloud-based scraping tools are becoming more popular, offering scalable and cost- effective solutions for businesses of all sizes. These platforms allow for the scraping of vast amounts of data without the need for extensive on- premises infrastructure.
Integration with Robotic Process Automation (RPA): RPA is increasingly being integrated with data scraping to automate repetitive tasks. This integration allows businesses to streamline data collection processes and improve efficiency.
Dynamic Data Extraction: The demand for real-time data is growing, particularly in industries like finance, e-commerce, and social media monitoring. Future scraping tools are likely to focus on real-time data extraction, enabling businesses to make quicker and more informed decisions.
Edge Computing: With the rise of edge computing, data scraping processes can be executed closer to the data source, reducing latency and improving the speed of data collection.
Privacy-First Scraping Techniques: As data privacy regulations become stricter, the development of privacy-first scraping techniques will be essential. These techniques will focus on anonymizing data, respecting user consent, and ensuring compliance with global privacy laws like GDPR and CCPA.
Ethical Scraping Practices: The future of data scraping will also see a greater emphasis on ethical practices, including transparent data collection methods and respect for intellectual property rights.
Automated Data Cleaning: To ensure that scraped data is useful, future tools will increasingly incorporate automated data cleaning processes. These will help eliminate errors, duplicates, and inconsistencies, providing businesses with high-quality data for analysis.
Enhanced Validation Mechanisms: Future trends may also include advanced validation mechanisms to ensure that the data being scraped is accurate, up-to-date, and reliable.
The future of data scraping and automation is promising, with emerging technologies like AI, cloud computing, and RPA significantly advancing the field. Businesses that embrace these innovations will be better equipped to leverage data scraping for informed decision-making and maintaining a competitive edge in their industries. However, it’s essential to balance these advancements with a commitment to ethical practices and compliance with evolving data privacy regulations.
Actowiz Solutions is here to help you navigate these changes with our cutting-edge data scraping services. Contact us today to harness the power of data scraping and stay ahead in your industry! You can also reach us for all your mobile app scraping, data collection, web scraping, and instant data scraper service requirements.
Yes, data scraping is a powerful tool for gathering competitive intelligence. By extracting data from competitor websites, businesses can monitor pricing, product offerings, customer reviews, and market trends. This information can be used to refine strategies, adjust pricing, and improve product development. However, it's crucial to ensure that scraping activities comply with legal and ethical guidelines, such as not violating a competitor's terms of service or scraping sensitive information. Data scraping helps businesses stay ahead of competitors by providing real-time insights, allowing them to make informed decisions based on the latest market data.
Data scraping enhances market research by providing access to vast amounts of real-time data from various online sources. Researchers can scrape data from social media, news websites, forums, and e-commerce platforms to gather insights into consumer behavior, market trends, and emerging industry developments. This data can be analyzed to identify patterns, track competitor activity, and predict future market movements. By automating the data collection process, businesses can save time and resources while ensuring they have the most up-to-date information to make strategic decisions. Web scraping is a crucial tool for comprehensive, data-driven market research.
Data scraping can pose security risks if not conducted properly. Scrapers can inadvertently access and scrape sensitive or confidential information, leading to data breaches. Additionally, poorly coded scraping tools can expose the scraping system to malware or phishing attacks. To mitigate these risks, it's essential to use secure, reliable tools and follow best practices, such as adhering to legal guidelines and respecting the website’s terms of service. Regularly updating and monitoring scraping tools can also help prevent security vulnerabilities, ensuring that the scraping process is both safe and effective.
Data scraping is extensively used in the financial services sector for activities such as tracking stock prices, monitoring economic indicators, and gathering data on competitors. Financial institutions use scraping tools to collect data from news sources, financial reports, and social media to assess market sentiment and make informed investment decisions. Additionally, scraping can help in fraud detection by identifying unusual patterns or activities. The ability to automate data collection allows financial institutions to stay updated with real-time data, enabling quick and accurate decision-making in a highly competitive environment.
The legality of data scraping varies by jurisdiction and depends on the website's terms of service and the type of data being scraped. While scraping publicly available data is generally legal, scraping private, sensitive, or copyrighted data without permission can lead to legal consequences. Many countries have data protection laws, such as GDPR in the EU, which regulate how personal data can be collected and used. Businesses should consult legal professionals to ensure compliance with local laws and regulations when engaging in data scraping activities, particularly when dealing with sensitive information.
Data scraping is invaluable for e-commerce businesses looking to stay competitive. By scraping product prices, customer reviews, and inventory levels from competitor websites, businesses can optimize their pricing strategies, improve product offerings, and enhance customer service. Scraping also helps e-commerce platforms monitor market trends and identify popular products. Additionally, scraping can be used to collect data for personalized marketing campaigns, driving customer engagement and sales. The ability to quickly gather and analyze large volumes of data gives e-commerce businesses a significant advantage in a rapidly changing market.
Web scraping and web crawling are related but distinct processes. Web crawling involves systematically browsing the internet to index web pages for search engines, whereas web scraping focuses on extracting specific data from web pages. Crawlers are used by search engines like Google to discover and index content, while scrapers are used by businesses to gather data for analysis. Web scraping typically involves targeted data extraction, using tools that interact with web pages to collect information such as product prices, user reviews, or social media posts.
Data scraping can be automated using specialized tools and scripts that schedule scraping tasks and continuously collect data from websites. Automation allows businesses to gather data at regular intervals, ensuring that they always have access to the most current information. Tools like web scraping APIs and custom scripts can be programmed to extract specific data, handle CAPTCHA challenges, and rotate IP addresses to avoid detection. Automation not only saves time but also increases the efficiency and accuracy of data collection, making it a vital component of modern data strategies.
Ethical data scraping involves respecting the privacy and intellectual property rights of others. Scrapers should avoid collecting personal or sensitive information without consent and should not scrape data from websites that explicitly prohibit it. Additionally, businesses should ensure that scraped data is used responsibly and in compliance with data protection regulations like GDPR. Transparency with users about how their data is being collected and used is also important. Ethical scraping practices help build trust with customers and avoid potential legal and reputational risks.
Businesses can use data scraping to enhance customer experience by collecting and analyzing customer feedback, reviews, and behavior patterns from various online platforms. This data can help identify areas for improvement in products or services, allowing businesses to address customer pain points more effectively. Additionally, scraping competitors’ data enables businesses to benchmark their offerings against industry standards and make data-driven decisions that improve customer satisfaction. By continuously monitoring and adapting to customer needs, businesses can create a more personalized and responsive customer experience, leading to increased loyalty and retention.
Our web scraping expertise is relied on by 4,000+ global enterprises including Zomato, Tata Consumer, Subway, and Expedia — helping them turn web data into growth.
Watch how businesses like yours are using Actowiz data to drive growth.
From Zomato to Expedia — see why global leaders trust us with their data.
Backed by automation, data volume, and enterprise-grade scale — we help businesses from startups to Fortune 500s extract competitive insights across the USA, UK, UAE, and beyond.






We partner with agencies, system integrators, and technology platforms to deliver end-to-end solutions across the retail and digital shelf ecosystem.







Aggregate RERA data across all 28 Indian states + UTs. Real-time project, builder, and compliance intelligence for India ?40+ trillion real estate market.

Discover how a Q-commerce startup saved ₹2.8 Cr annually by tracking Blinkit, Zepto, and Instamart in real time. Learn how data-driven pricing and inventory insights boost efficiency and profitability.

Scrape In-N-Out Burger locations data in the USA in 2026 to analyze store expansion, regional coverage, and market trends.
Whether you're a startup or a Fortune 500 — we have the right plan for your data needs.



 E-commerce & Retail
E-commerce & Retail Grocery & FMCG
Grocery & FMCG Travel & Hospitality
Travel & Hospitality Food & Restaurants
Food & Restaurants Finance & Legal
Finance & Legal Healthcare & Pharma
Healthcare & Pharma Real Estate & Local
Real Estate & Local Automotive & Mobility
Automotive & Mobility Media & Entertainment
Media & Entertainment Emerging Industries
Emerging Industries




























