Actowiz Metrics Real-time  analytics dashboard for brands! Try Free Demo
analytics dashboard for brands! Try Free Demo
Scalable web, app & AI-powered extraction. 99.9% accuracy.
All Services → Core Scraping Services
Core Scraping Services
 Top Global Platforms
Top Global Platforms
 Platforms by Region
Platforms by Region
🇦🇪 Expanding across UAE, Saudi, Qatar, Kuwait & more
Request Custom Platform →🌏 Singapore, Indonesia, Thailand, Philippines, Vietnam & Malaysia
Request Custom Platform →🌎 Brazil, Mexico, Argentina, Colombia & Chile
Request Custom Platform → Pricing & Promotions
Pricing & Promotions
 Brand & Intelligence
Brand & Intelligence
 Digital Shelf & Search
Digital Shelf & Search
 Assortment
Assortment For Retailers
For RetailersWhich solution fits?
Talk to Expert Marketplace Scrapers
Marketplace Scrapers
 Data APIs
Data APIs Universal APIs
Universal APIs Delivery & SDKs
Delivery & SDKsReady to integrate?
Start Free Trial Knowledge Center
Knowledge Center
 Guides & Playbooks
Guides & Playbooks
 Downloads & Tools
Downloads & Tools
 Trust & Company
Trust & CompanyScalable web, app & AI-powered extraction. 99.9% accuracy.
All Services → Core Scraping Services
Top Global Platforms
Pricing & Promotions
Brand & Intelligence
Digital Shelf & Search
Assortment For RetailersWhich solution fits?
Talk to Expert Marketplace Scrapers
Data APIs Universal APIs Delivery & SDKsReady to integrate?
Start Free Trial Knowledge Center
Guides & Playbooks
Downloads & Tools
Trust & Company
In this blog, we will see how to extract Flipkart product data using BeautifulSoup and Python in an easy and sophisticated manner.
This blog aims to do real-world problem-solving while keeping that very simple so that you become familiar with and have practical results quickly.
After that, install BeautifulSoup using:

Also, we will need lxml, library requests, and soupsieve to get data, split it down into XML, and apply CSS selectors. Then, install those.

When get installed, open the editor and type:

That’s how it will look:
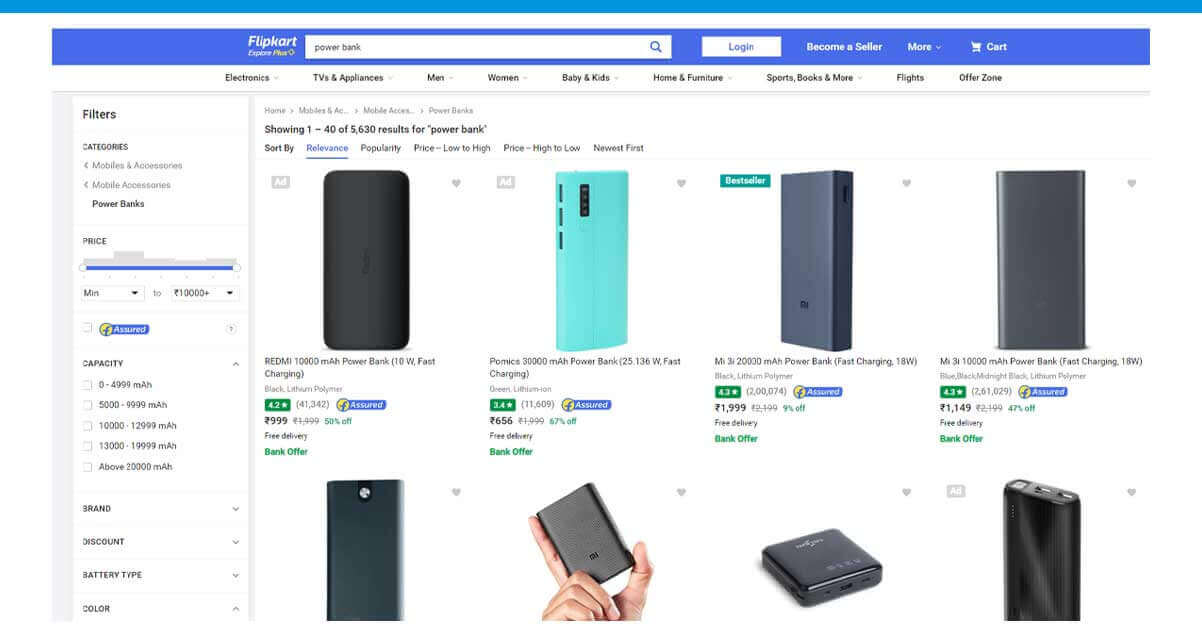
Coming back to code, let's get data by imagining that we have a browser like this:

Save that as scrapeFlipkart.py.
In case you run that:

You would see the entire HTML page.
Let's utilize CSS selectors to get the desired data. To do it, let's come back to Chrome and open it inspect tool.
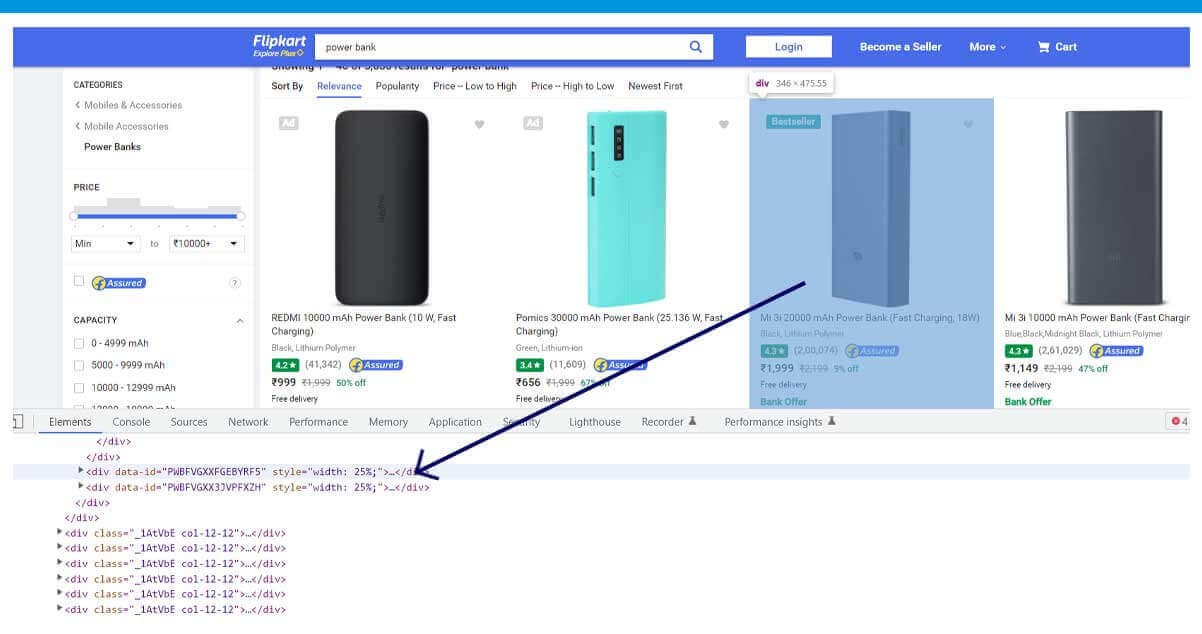
We observe that all individual product data are controlled with an attribute data-id. You also follow that the attribute's value is nonsense and keeps changing. So, we can't use that. However, the evidence is the occurrence of the data-id attribute. So let's scrape it.

It prints all content in all containers which hold product data.

Let’s get back to work in all the desired fields. It is challenging as Flipkart HTML doesn’t have any meaningful CSS classes to use. Therefore, we would resort that to a few tricks, which might be dependable.
For title, we have noticed that the initial anchor tag comes with an image within it that always has a title in the alt attribute. Therefore, let's get it.

The subsequent line above provides us a URL to listing.
The product ratings have a meaningful id productRating trailed by some nonsense. However, we can utilize the *= operator for selecting anything that has a word called productRating:

Extracting the price data is more challenging as this has no visible class ID or name like a clue of getting to it. However, it always provides a currency denominator having ₹ in that. Therefore, we utilize regex to discover it.

Here, we do same to have a discount percentage. This always has a word off in that.

Putting that together.

In case you run that, it would print all the information.
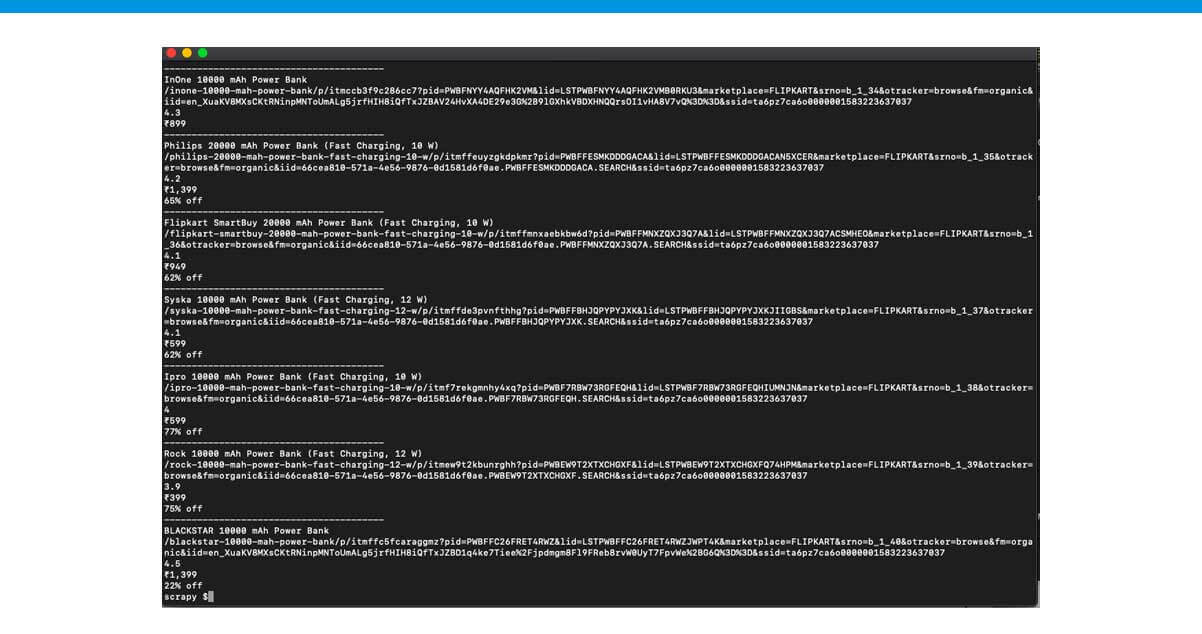
And Kudos!! We have them all. This was challenging yet satisfying.
If you need to use that in production or wish to measure thousands of links, you will get that you will have your IP blocked effortlessly by Flipkart. With this condition, using rotating proxy services to rotate different IPs is essential. You can utilize services like Proxies APIs to send calls through the pool of millions of proxies.
In case you need to scale up crawling speed and you don’t want to have the infrastructure; you can utilize our data crawler to easily extract thousands of URLs with higher speed from network of crawlers.
For more information about Flipkart product data scraping, contact us now! We also provide mobile app scraping and web scraping services at a reasonable price!
Our web scraping expertise is relied on by 4,000+ global enterprises including Zomato, Tata Consumer, Subway, and Expedia — helping them turn web data into growth.
Watch how businesses like yours are using Actowiz data to drive growth.
From Zomato to Expedia — see why global leaders trust us with their data.
Backed by automation, data volume, and enterprise-grade scale — we help businesses from startups to Fortune 500s extract competitive insights across the USA, UK, UAE, and beyond.






We partner with agencies, system integrators, and technology platforms to deliver end-to-end solutions across the retail and digital shelf ecosystem.







How Blinkit and Zepto use pricing, dark store, and SKU data to win India 10-minute delivery war � and how FMCG brands can track both platforms with quick commerce intelligence.

Case study on how we used Adidas Product Data Scraping to help a brand gain insights, optimize pricing, and drive competitive intelligence.

Scrape 10 largest pizza chains Data in the United States in 2026 to analyze pricing, menus, trends, and market share for smarter insights.
Whether you're a startup or a Fortune 500 — we have the right plan for your data needs.



 E-commerce & Retail
E-commerce & Retail Grocery & FMCG
Grocery & FMCG Travel & Hospitality
Travel & Hospitality Food & Restaurants
Food & Restaurants Finance & Legal
Finance & Legal Healthcare & Pharma
Healthcare & Pharma Real Estate & Local
Real Estate & Local Automotive & Mobility
Automotive & Mobility Media & Entertainment
Media & Entertainment Emerging Industries
Emerging Industries




























