
Introduction
In the ever-expanding realm of e-commerce, staying ahead of the curve requires quick access to product information, market trends, and consumer insights. As one of the world's largest online marketplaces, Amazon holds a treasure trove of valuable data. Leveraging ChatGPT for automated Amazon web scraping provides a powerful solution for gathering the information you need efficiently and effectively.
This comprehensive tutorial will guide you through using ChatGPT to automate web scraping on Amazon. By the end of this journey, you'll have the knowledge and tools to extract product details, pricing information, customer reviews, and more from Amazon's vast digital aisles.
Our tutorial covers the entire web scraping workflow, from setting up your environment and understanding the Amazon website's structure to deploying ChatGPT for automated data extraction. You don't need to be a programming expert to follow along; we'll provide step-by-step instructions and code snippets to simplify the process.
Additionally, we'll explore best practices and potential challenges, ensuring that your web scraping endeavors are ethical and practical. By the end of this tutorial, you'll have a powerful tool at your disposal, capable of keeping you informed about market trends, competitor activities, and consumer sentiments on the world's largest online marketplace. So, let's embark on this journey to unlock the data-driven potential of Amazon web scraping with ChatGPT.
The Sequential Stages of Web Scraping
Web scraping involves several steps:
Identify Data Source: Determine the website or online resource you want to extract data from.
Understand the Structure: Analyze the website's structure, identifying the specific elements or sections containing the desired data.
Select a Tool or Framework: Choose a web scraping tool or framework suitable for your needs, such as Beautiful Soup, Scrapy, or Selenium.
Develop or Configure the Scraper: Develop a script or configure the tool to navigate the website and extract the targeted data, specifying the elements to be collected.
Access and Extract Data: Execute the scraper to access the website and retrieve the desired information.
Data Cleaning and Processing: Clean and process the extracted data to remove inconsistencies, format it, and prepare it for analysis.
Storage and Analysis: Save the scraped data in a suitable format (like CSV, JSON, or a database) and analyze it to derive insights or for further use.
Monitoring and Maintenance: Regularly monitor the scraper's performance, ensure compliance with website terms of service, and make necessary adjustments to maintain data accuracy and consistency.
Ethical Considerations: Adhere to ethical scraping practices, respect website terms of service, and avoid overloading the site's servers to maintain a fair and respectful approach to data extraction.
Each step requires careful consideration and technical know-how to ensure successful and ethical web scraping.
Behavior and Characteristics Before Starting a Web Scraping Procedure
Before initiating the web scraping process, it's crucial to comprehend the diverse types of websites, considering their distinctive characteristics and behaviors. Understanding these aspects is pivotal for selecting the appropriate tools and techniques to retrieve desired data effectively. Key distinctions include:
Specify Website and Data
- Provide the URL or describe the structure/content of the website you want to scrape.
- Clearly state the specific data elements, sections, or patterns you wish to extract.
Preferred Scraping Tool
- Indicate if you have a preferred web scraping tool or library (e.g., BeautifulSoup, Scrapy).
- Alternatively, leave it open-ended for ChatGPT to suggest a suitable library based on your needs.
Website Characteristics
- Identify the type of website based on its behavior.
- Static Websites: Fixed content, stable HTML structure.
- Dynamic Websites: Content changes dynamically based on user interactions.
- JavaScript Rendering: Heavy reliance on JavaScript for content rendering.
- Captchas/IP Blocking: Additional measures may be needed to overcome obstacles.
- Login/Authentication: Proper authentication techniques required.
- Pagination: Handling required for scraping across multiple pages.
Handling Different Website Types
- For static websites, BeautifulSoup is recommended for efficient parsing and navigation.
- For dynamic websites, consider using Selenium for browser automation.
- Websites with JavaScript rendering may benefit from Playwright due to its powerful capabilities.
Example Scenario - Amazon
- Demonstrate the use case with an example: scraping Amazon's product page for kids' toys.
- Highlight the need for advanced tools for handling dynamic content on e-commerce sites.
- Mention suitable options: BeautifulSoup with requests-HTML, Selenium, Scrapy, and Playwright.
Additional Constraints or Requirements
- Specify any constraints like Captchas, IP blocking, or specific handling requirements.
- Note if the website requires login/authentication for accessing desired data.
- By providing precise information on these points, you'll receive more accurate and relevant guidance or code snippets for your web scraping task.
Leveraging Chat GPT for Amazon Website Scraping
The initial stage of web scraping involves extracting product URLs from an Amazon webpage. To achieve this, locating the URL element on the page associated with the desired product is essential. The first step is to examine the webpage's structure. To inspect components, right-click on any element of interest and choose the "Inspect" option from the context menu. This action enables us to scrutinize the HTML code, facilitating the identification of the necessary data for the web scraping process.
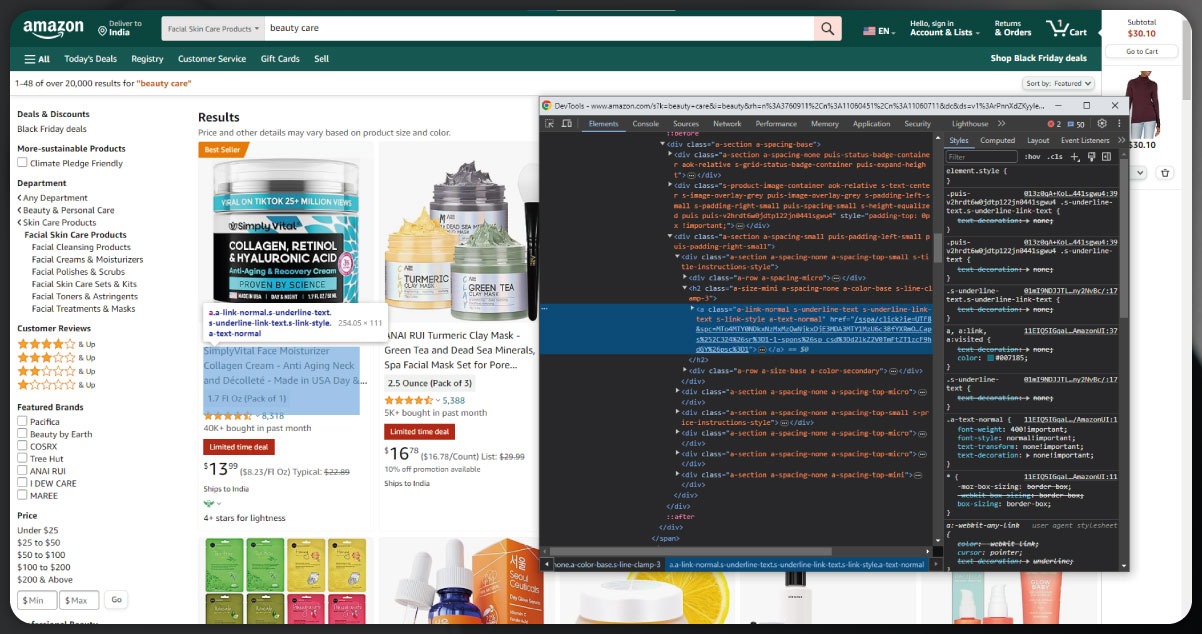
To generate the code, simply left-click on the content of the relevant URLs and copy it. In this process, we will utilize Beautiful Soup for web scraping, a powerful Python library that facilitates efficient parsing and navigation of HTML documents.
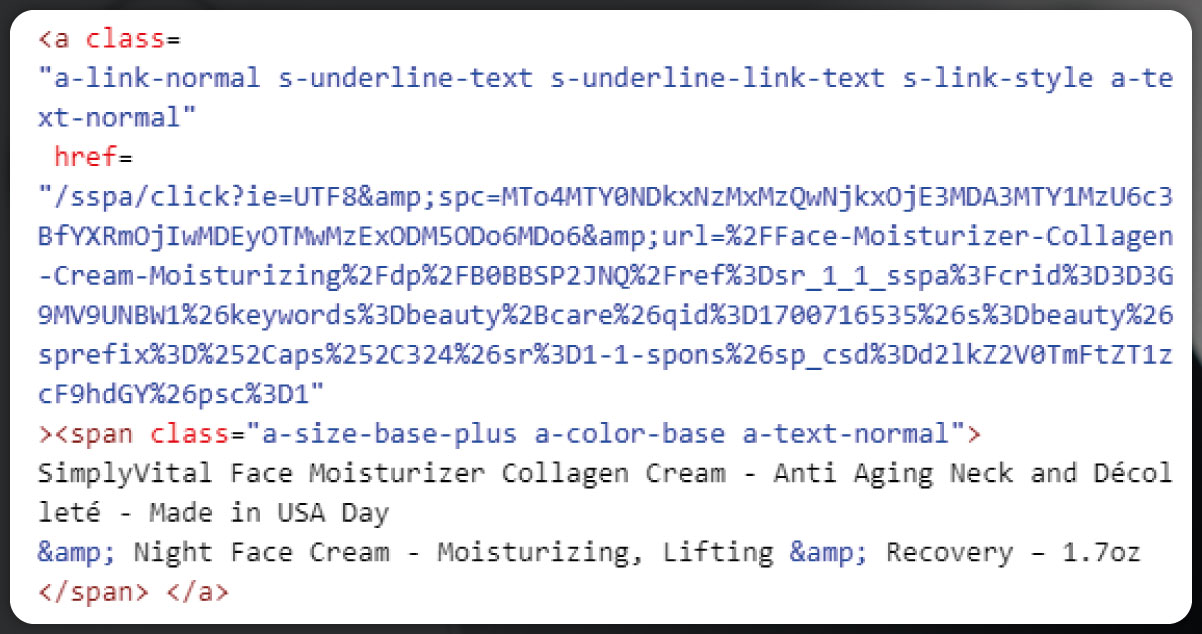
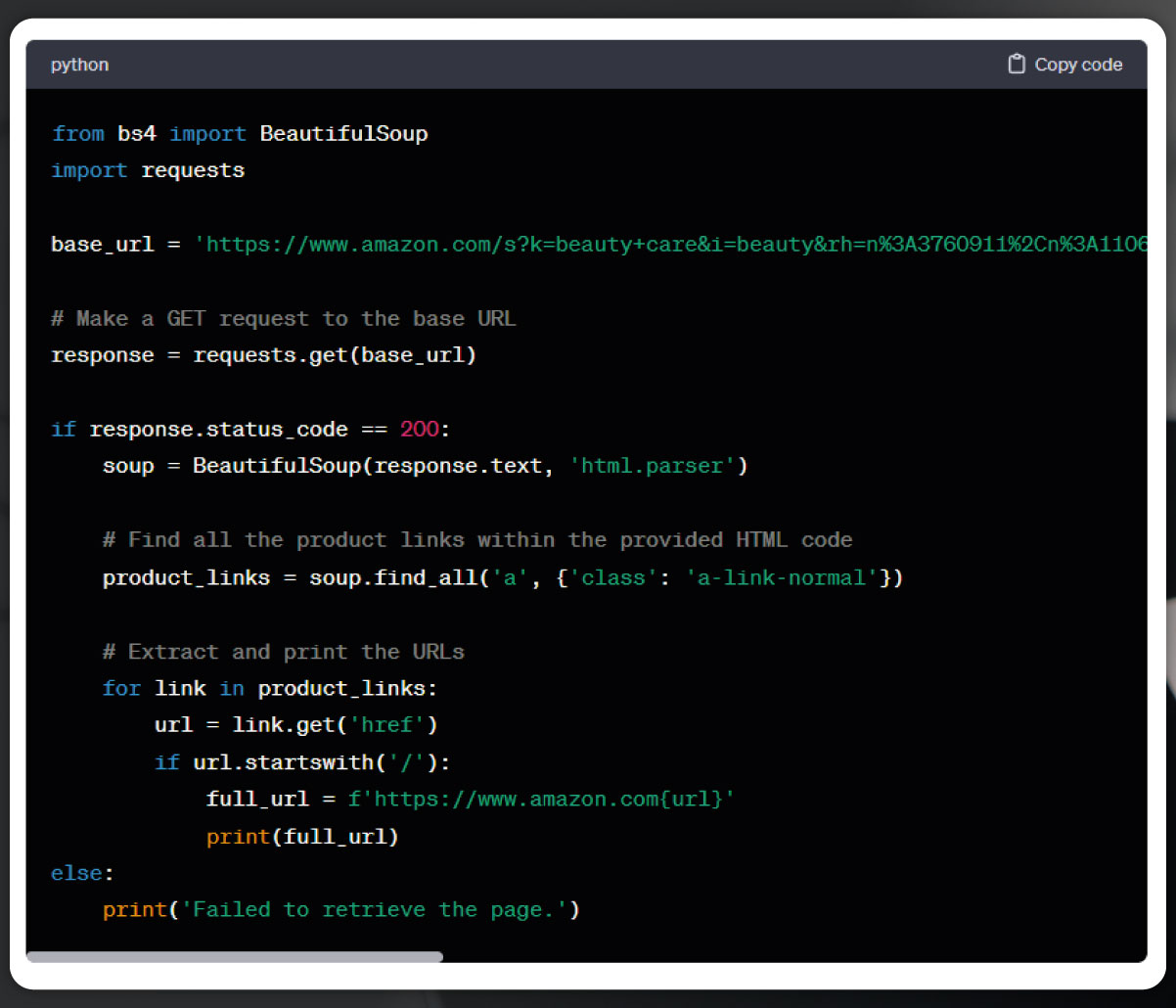
Importing Libraries
- Begin by importing necessary libraries, such as requests for handling web requests and BeautifulSoup for HTML parsing in Python.
Setting Base URL
- Set the base URL to the Amazon India search page for "toys for kids."
Sending HTTP Request
- Utilize the Python requests library to send a request to the base URL.
Handling Response
- Store the response in the 'response' variable for further processing.
Creating BeautifulSoup Object
- Create a BeautifulSoup object from the response content using the HTML parser library.
CSS Selector for URLs
- Generate a CSS selector to locate the URLs of products listed under the category of "toys for kids."
Finding Anchor Elements
- Use BeautifulSoup's 'find_all' method to search for all anchor elements (links) based on the CSS selector.
Extracting and Building URLs
- Initialize an empty list named 'product_urls' to store the extracted URLs.
- Execute a for loop to iterate through each element in 'product_links.'
- Extract the 'href' attribute for each element using BeautifulSoup's 'get' method.
- If a valid 'href' is found, append the base URL to form the complete URL of the product.
- Add the full URL to the 'product_urls' list.
Printing Extracted URLs
- Print the list of extracted product URLs to ensure successful extraction.
Following these steps, the code effectively extracts and prints the URLs of products listed under the specified category on the Amazon webpage.
In this scenario, a CSS selector is employed to pinpoint the element on the Amazon product page. While CSS selectors are commonly used, developers may opt for alternative methods like XPath. If you prefer XPath, mention "using XPath" in your initial prompt to ChatGPT for tailored code generation.
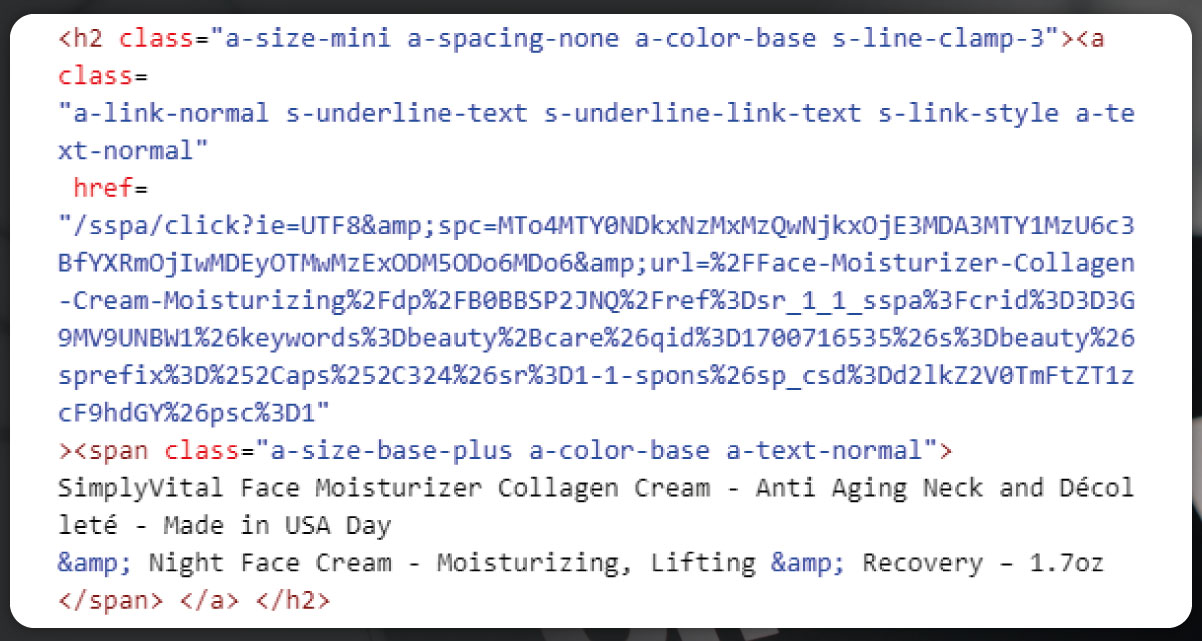

In the targeted category with numerous products featuring unique URLs, we aim to extract data from individual pages, specifically product description pages. To address pagination, the approach involves inspecting the "next" button and copying its content to prompt ChatGPT for tailored guidance. This strategy ensures systematic data retrieval from each product's dedicated page while efficiently handling the pagination challenge.
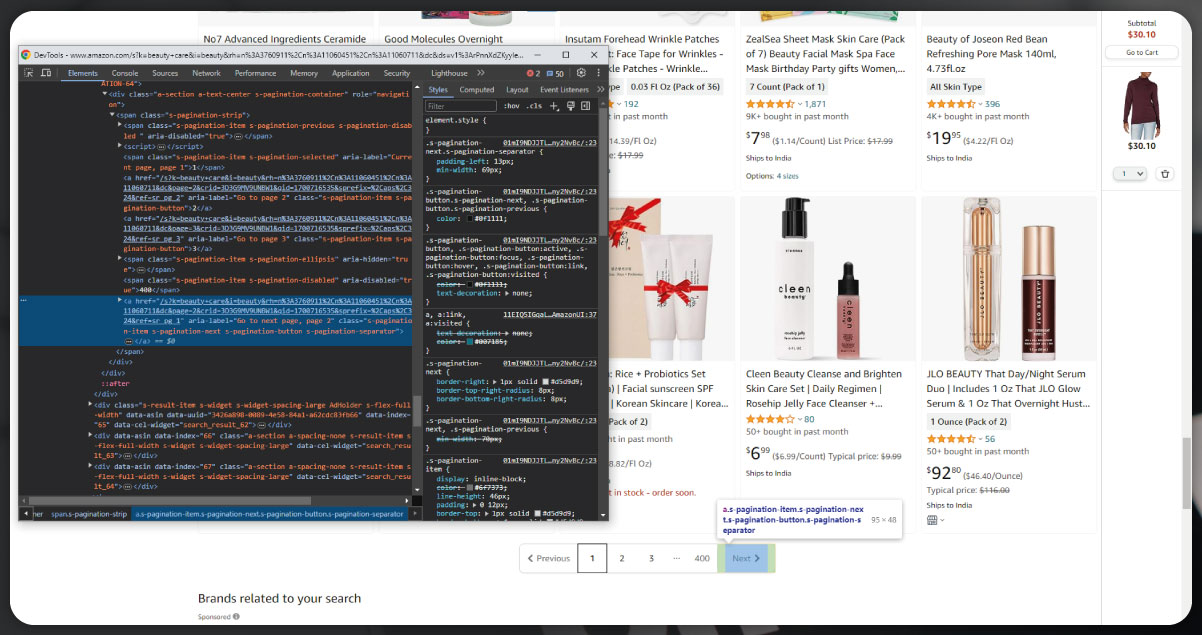
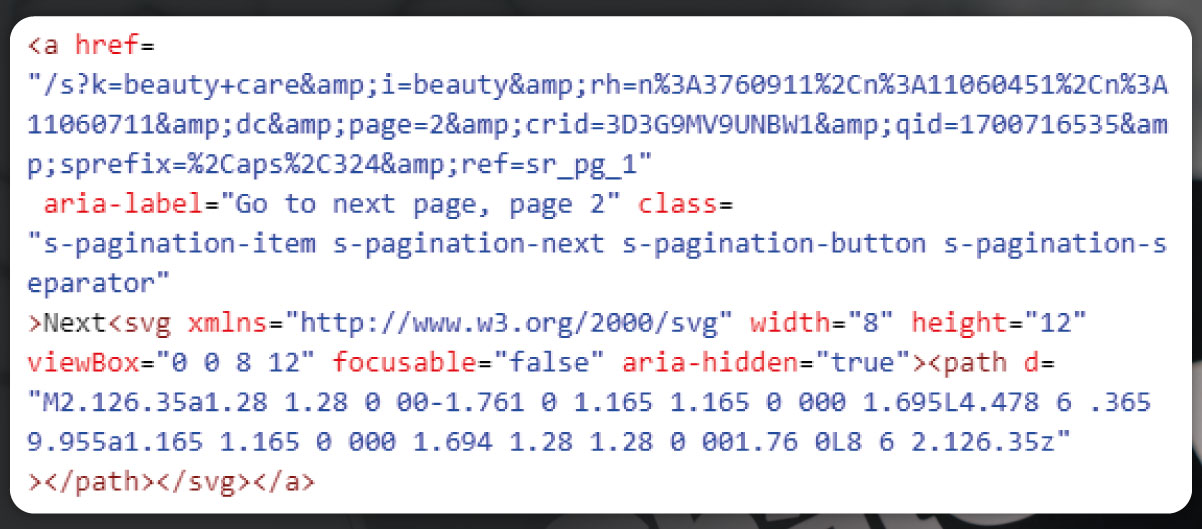
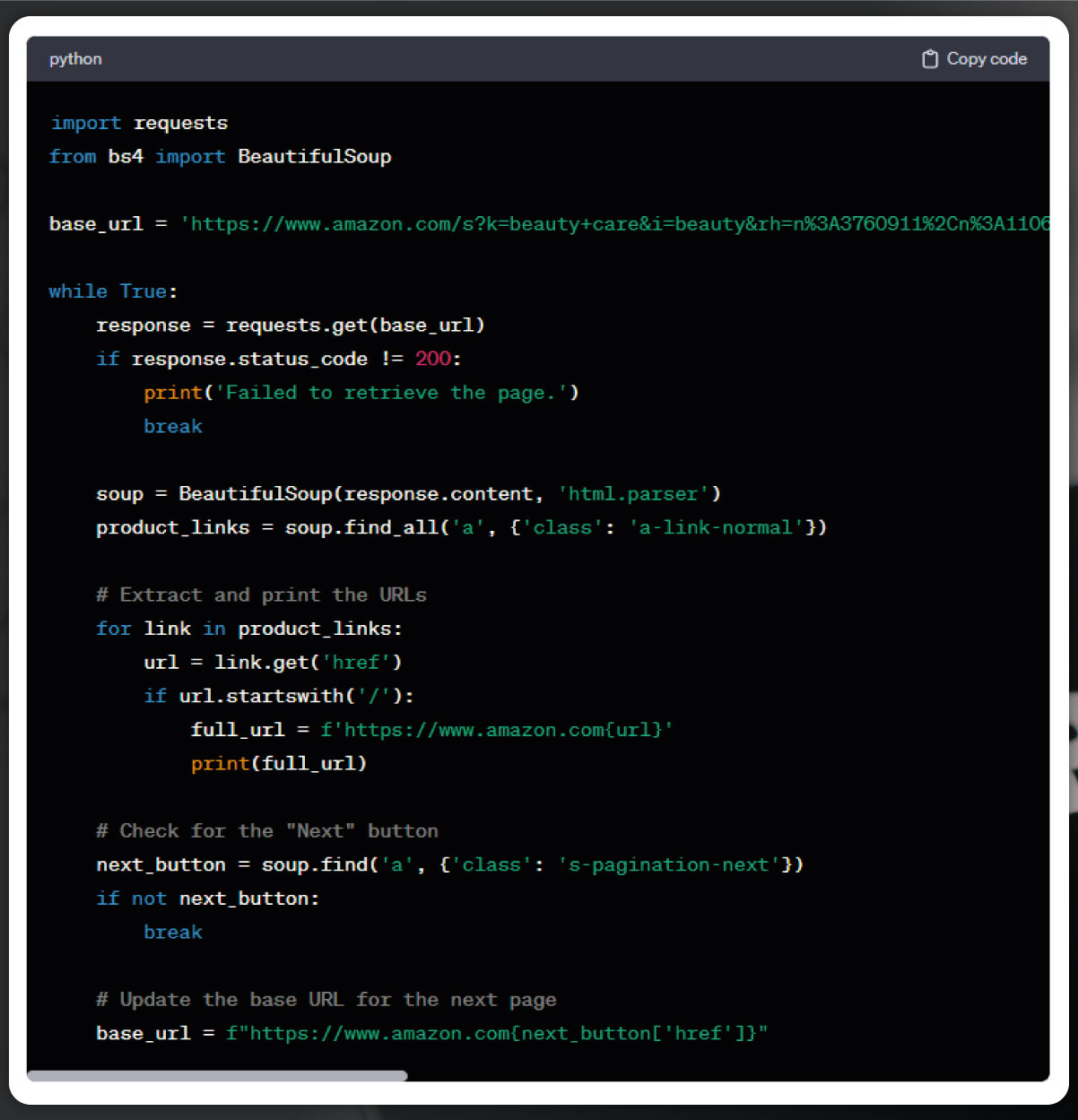
The provided code extends the initial snippet to scrape product URLs from multiple pages of Amazon search results. Initially, only product URLs from category pages were extracted. The extension introduces a while loop to iterate through multiple pages, addressing pagination concerns. The loop continues until no "Next" button is available on the page, indicating all available pages have been scraped. It checks for the "Next" button using BeautifulSoup's find method. If found, the URL for the next page is extracted and assigned to next_page_url. The base URL is then updated, allowing the loop to progress. Should the absence of a "Next" button indicate the conclusion of available pages, the loop terminates, and the script proceeds to print the comprehensive list of scraped product URLs.
After successfully navigating an Amazon category, the next step is extracting product information for each item. To accomplish this, an examination of the product page's structure is necessary. By inspecting the webpage, specific data required for web scraping can be identified. Locating the appropriate elements enables the extraction of desired information, facilitating the progression of the web scraping process. This iterative approach ensures comprehensive data retrieval from various pages while effectively handling pagination intricacies on the Amazon website.
Now, let's delve into the process of extracting product names through web scraping.
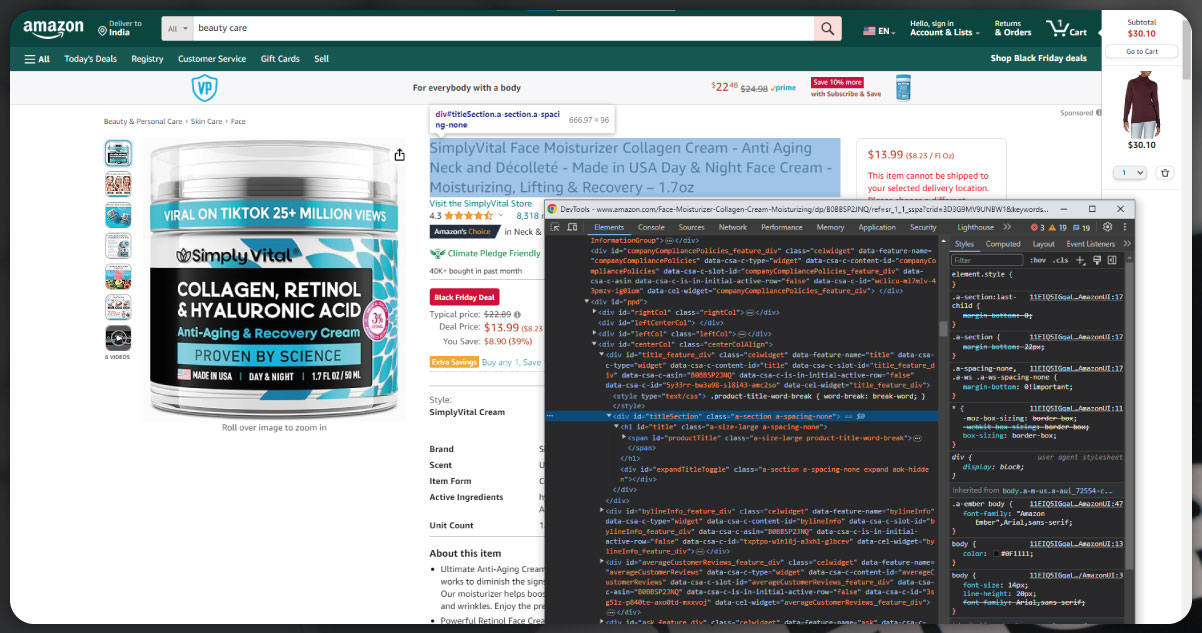
Usually, the approach involves inspecting product names and copying their content in the customary manner to facilitate the web scraping process.

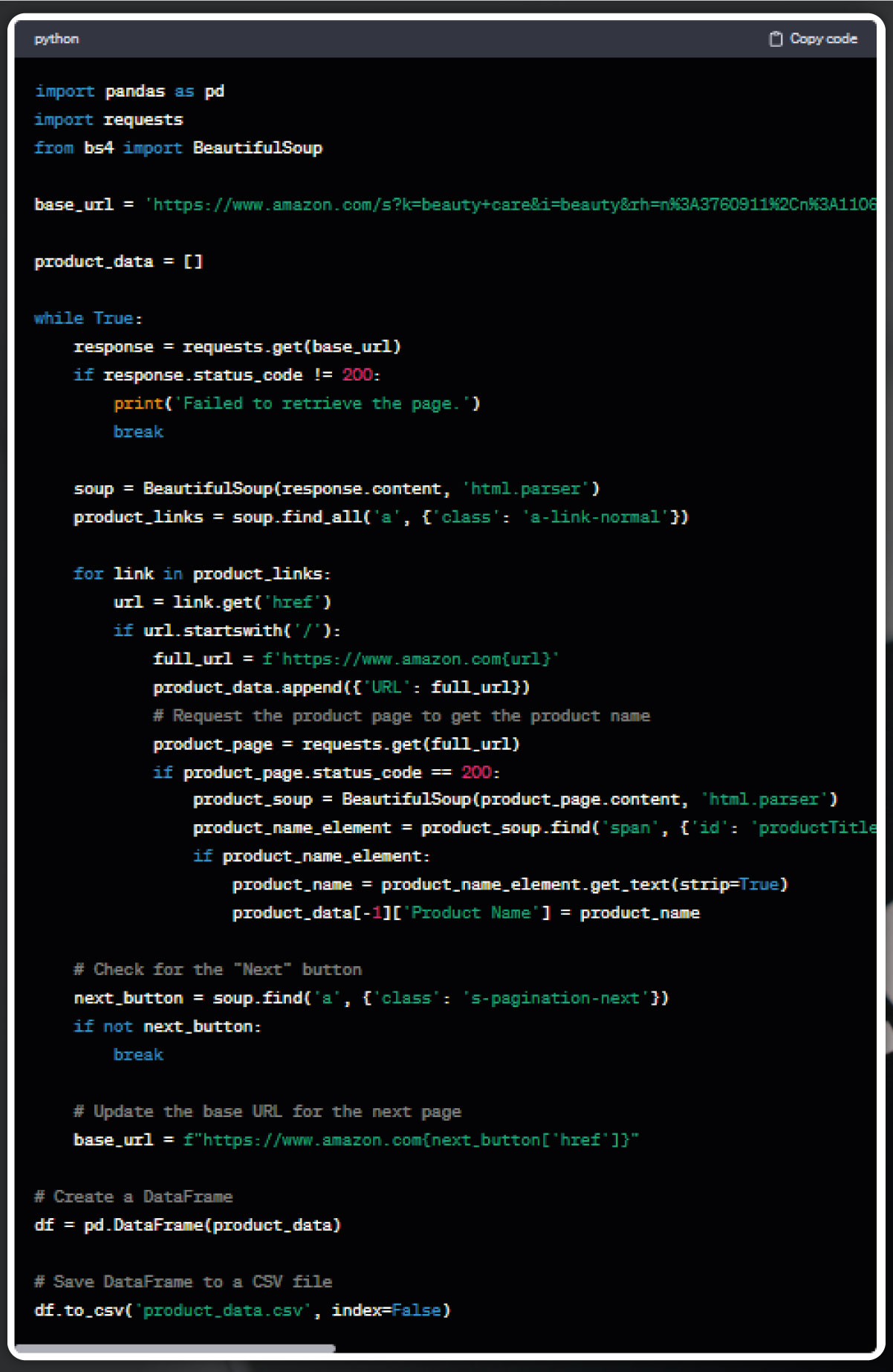
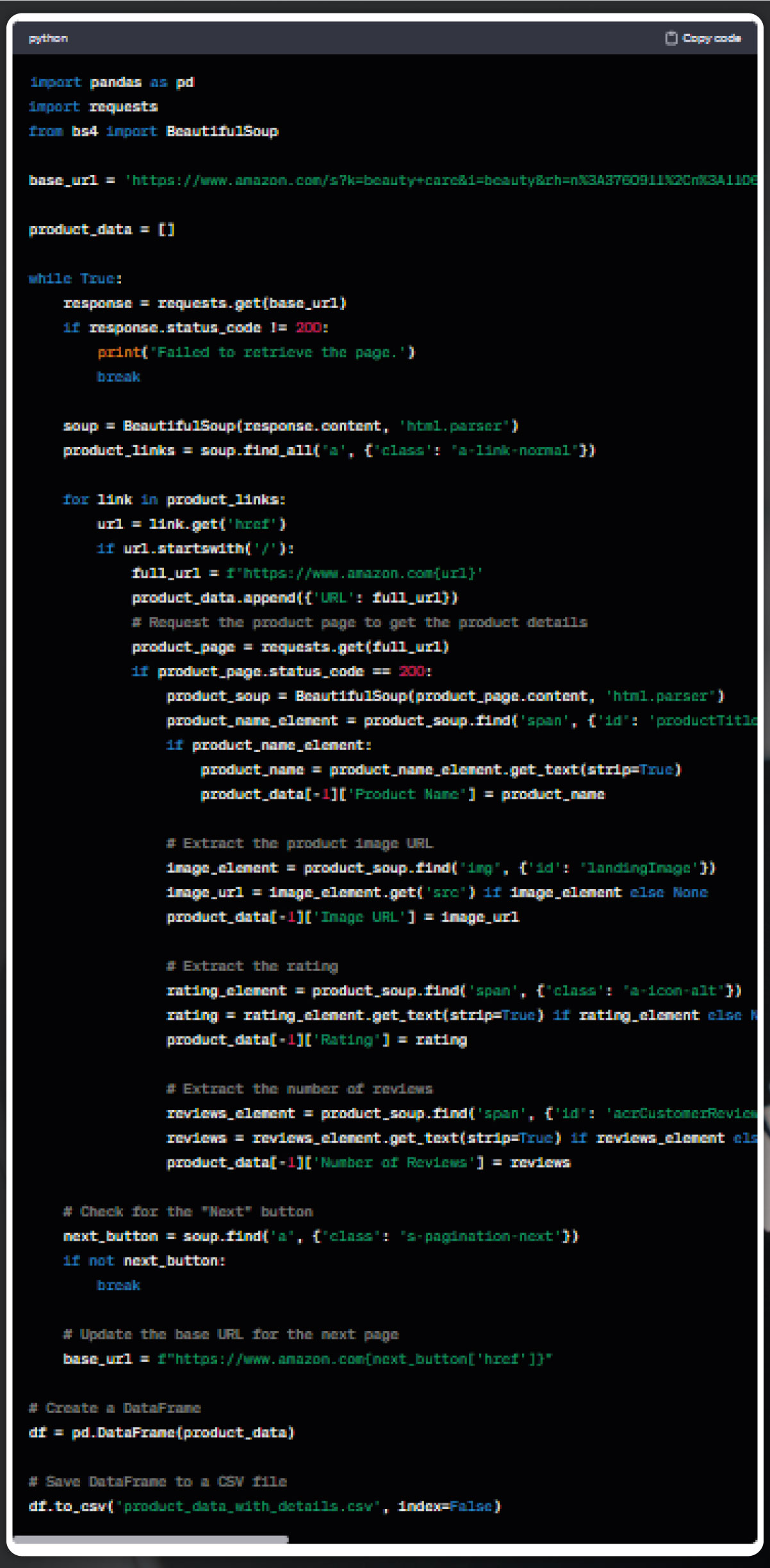
In this enhanced code snippet, the web scraper is refined to extract product URLs and capture product names. Additionally, it incorporates the Pandas library to create a structured data frame from the accumulated data, ultimately saving it to a CSV file. In the subsequent part of the code, after appending every product’s URL to a product_data list, a request is made to the respective product URL. Subsequently, the code identifies the element containing the product name, extracts it, and appends it to the product_data list alongside the product URL.
Upon completing the scraping process, Pandas transforms the product_data list into a DataFrame, effectively organizing product URLs and names into distinct columns. This DataFrame serves as a structured representation of the scraped data. Finally, the entire data frame gets saved in the CSV file called 'product_data.csv,' ensuring convenient storage and accessibility of the extracted information.
Similarly, the process can be extended to extract the price of each product. Typically, inspecting the price and customarily copying its content would facilitate the subsequent steps in the web scraping process. This comprehensive approach ensures the systematic extraction and organization of crucial product information.
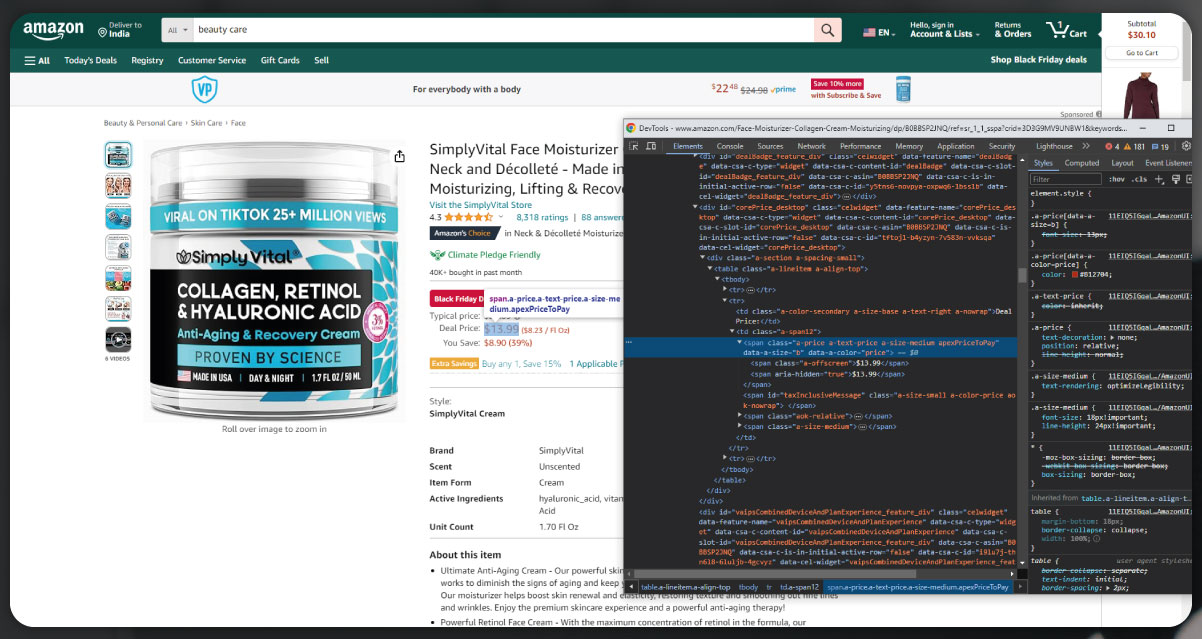

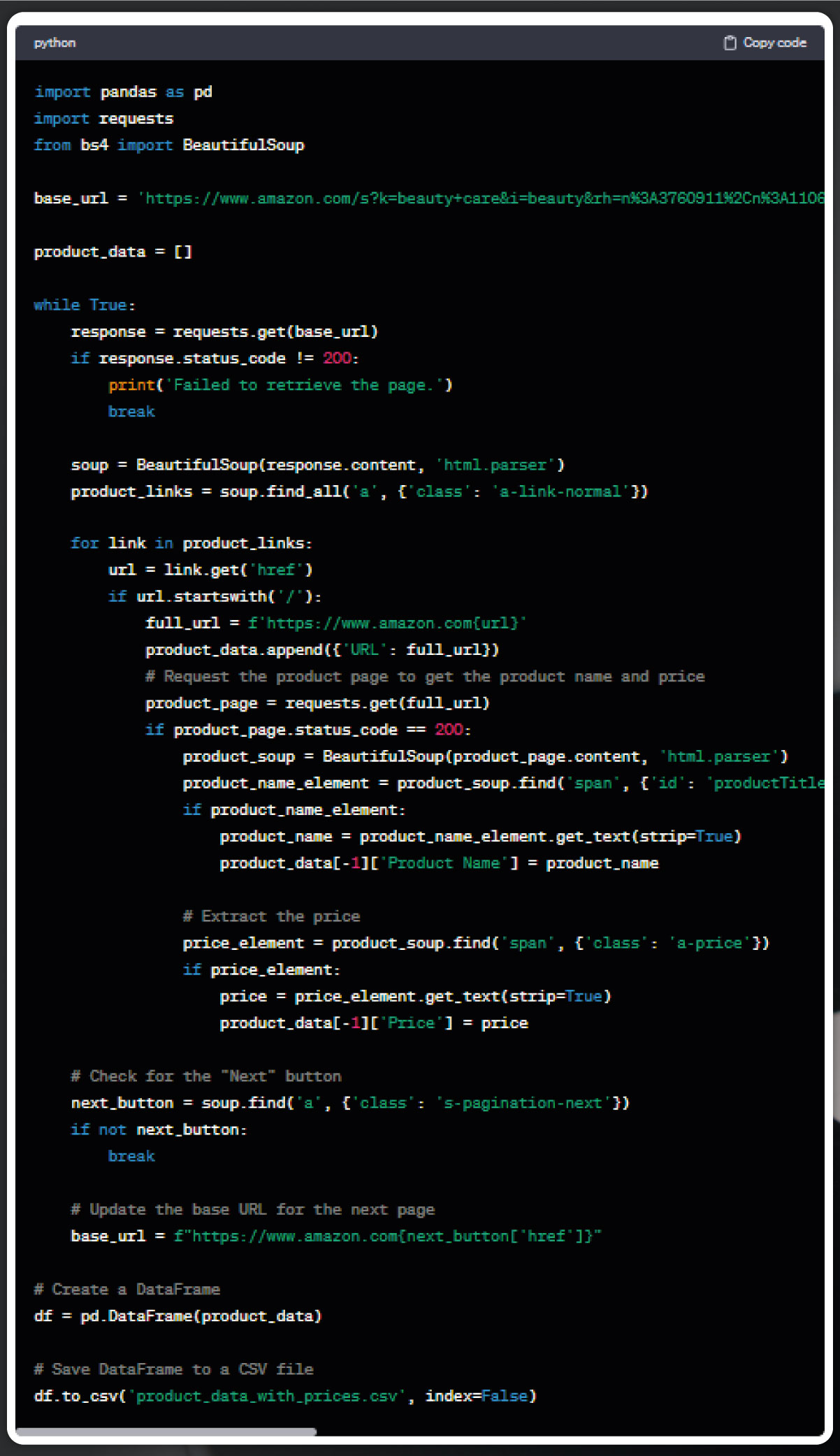
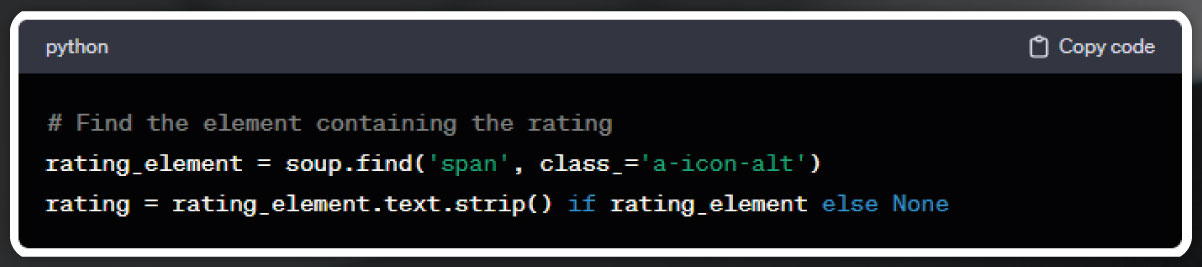
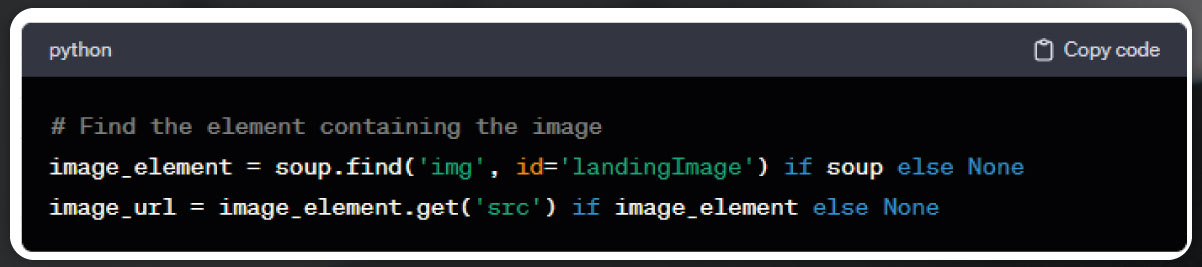
Similarly, we can extract various product details, including rating, number of reviews, images, and more. Let's specifically focus on the extraction of product ratings for now.
Ratings
Total Reviews
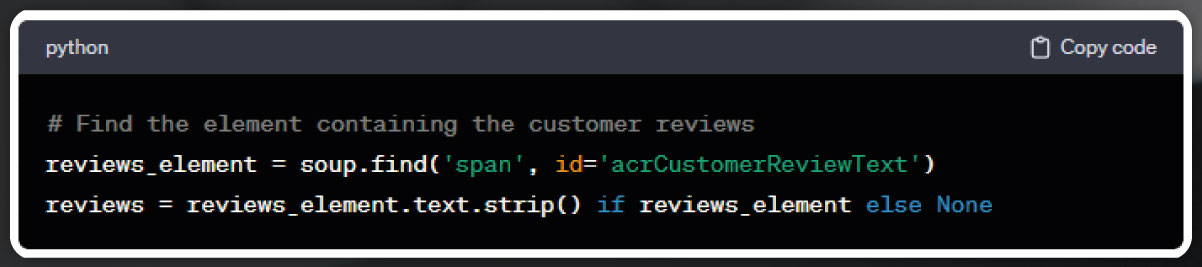
Image
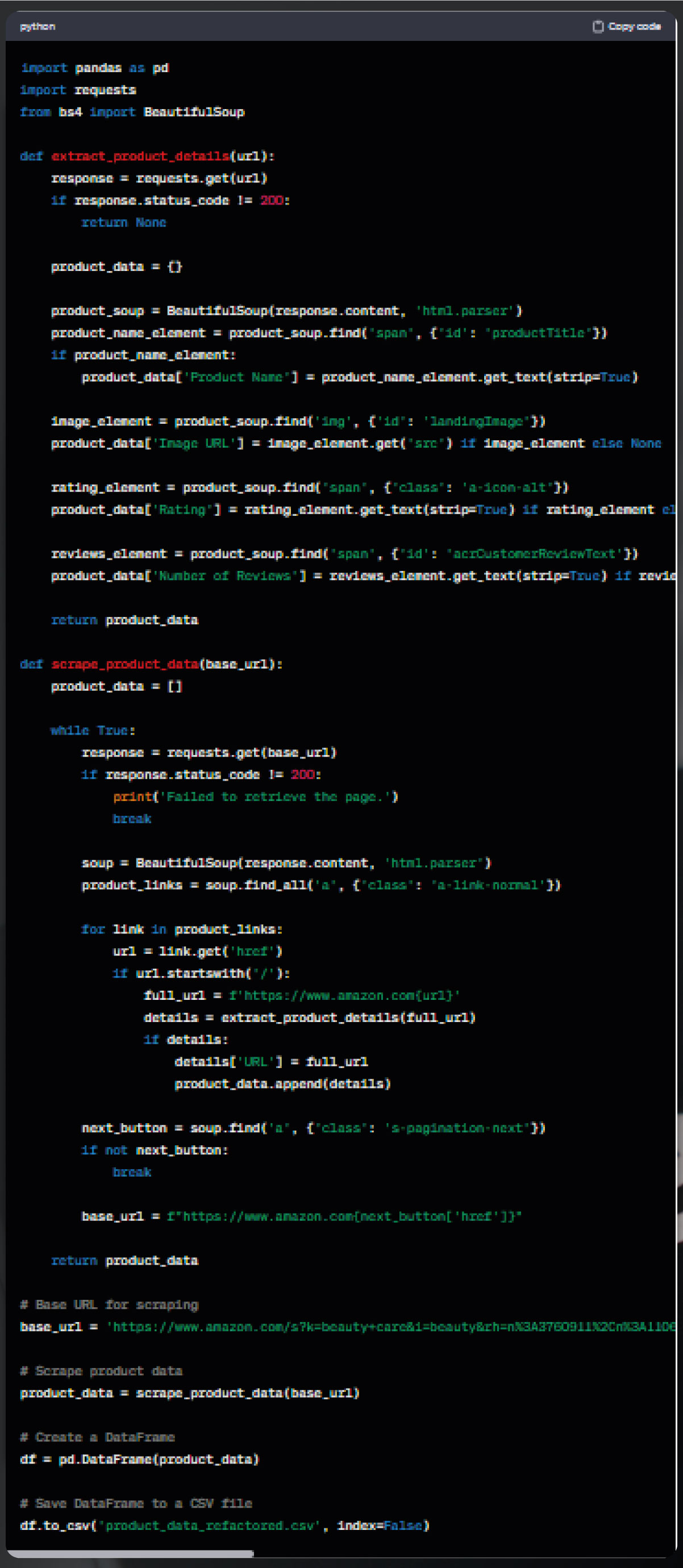
Let's enhance the code for improved readability, maintainability, and efficiency while preserving its external behavior.
Challenges and Limitations in Web Scraping with ChatGPT
While ChatGPT can offer valuable assistance in generating code and providing guidance for web scraping, it has limitations in this context. Understanding these constraints is crucial for ensuring successful and effective web scraping endeavors.
Limited Interactivity
ChatGPT operates in a conversational mode, generating responses based on input prompts. However, it cannot interact directly with web pages or dynamically respond to changes during the scraping process. Real-time interactions and adaptations may require a more interactive environment.
Lack of Browsing Capability
Unlike web scraping tools like Selenium, ChatGPT cannot simulate browser interactions, handle dynamic content, or execute JavaScript. This makes it less suitable for scenarios where web pages heavily rely on client-side rendering.
Complex Scenarios Handling
Web scraping tasks often involve handling complex scenarios like login/authentication, overcoming captchas, or dealing with websites that implement anti-scraping measures. These challenges may go beyond the capabilities of ChatGPT, requiring specialized techniques or tools.
Dependency on Prompt Quality
The effectiveness of the generated code heavily depends on the quality and clarity of the prompts provided to ChatGPT. Ambiguous or unclear prompts may result in code that requires additional refinement or correction.
Security Concerns
ChatGPT may inadvertently generate code that raises security concerns, especially when dealing with sensitive data or with websites with security measures. Reviewing and validating the generated code for potential security risks is crucial.
Handling Large Datasets
While ChatGPT can assist in code snippets, handling large datasets efficiently often requires considerations for memory management, storage, and processing optimizations. These aspects might need to be explicitly addressed in the generated code.
Limited Error Handling
The generated code might need comprehensive error-handling mechanisms. In real-world web scraping scenarios, it's essential to implement robust error-handling strategies to manage unexpected situations and prevent disruptions.
Evolution of Web Technologies
Web technologies are constantly evolving, and new trends may introduce challenges ChatGPT might need to learn or be equipped to handle. Staying updated on best practices and emerging technologies is essential for successful web scraping.
Ethical and Legal Considerations
ChatGPT may not guide ethical or legal considerations related to web scraping. Users must be aware of and adhere to ethical standards, terms of service of websites, and legal regulations governing web scraping activities.
While ChatGPT can be a valuable resource for generating code snippets and providing insights, users should be aware of its limitations and complement its assistance with domain-specific knowledge and best practices in web scraping.
Navigating the Limitations of ChatGPT for Web Scraping: A Practical Perspective
ChatGPT generates fundamental web scraping code, but its suitability for production-level use has limitations. Treating the generated code as a starting point, thoroughly reviewing it, and adapting it to meet specific requirements, industry best practices, and evolving web technologies is crucial. Enhancing the code may necessitate personal expertise and additional research. Moreover, adherence to legal and ethical considerations is essential in web scraping endeavors.
Striking a Balance: ChatGPT and Web Scraping Best Practices
While ChatGPT serves beginners or one-time copying projects well, it falls short for regular data extraction or projects demanding refined web scraping code. In such cases, consulting professional web scraping companies like Actowiz Solutions, with expertise in the field, is recommended for efficient and compliant solutions.
Conclusion
Web scraping is vital in data acquisition, yet it can be daunting for beginners. LLM-based tools, such as ChatGPT, have significantly increased accessibility to web scraping.
ChatGPT serves as a guiding companion for beginners entering the realm of web scraping. It simplifies the process, offering detailed explanations and building confidence in data extraction. By adhering to step-by-step guidance and utilizing tools such as BeautifulSoup, Selenium, or Playwright, newcomers can proficiently extract data from websites, enabling well-informed decision-making. Despite the inherent limitations of ChatGPT, its value extends to beginners and seasoned users in the web scraping domain.
For those seeking reliable web scraping services to meet their data requirements, Actowiz Solutions stands as a trustworthy option. For more details, contact us! You can also reach us for all your mobile app scraping, instant data scraper and web scraping service requirements.
 Core Scraping Services
Amazon Data Scraping #1 Walmart Data Scraping Shopify Store Scraping HOT TikTok Shop Scraping HOT Flipkart Data Scraping
Core Scraping Services
Amazon Data Scraping #1 Walmart Data Scraping Shopify Store Scraping HOT TikTok Shop Scraping HOT Flipkart Data Scraping Top Global Platforms
Top Global Platforms
 Platforms by Region
🇺🇸 USA🇬🇧🇪🇺 UK/EU🇮🇳 India🇦🇪 ME🌏 SEA🌎 LATAM🇨🇳🇯🇵🇰🇷🇦🇺 AUAmazon Data Scraping #1 Walmart Data Scraping Target Data Scraping NEW Shopify Scraping HOT TikTok Shop Scraping HOT Costco Data Scraping NEW Best Buy Scraping NEW Home Depot Scraping NEW Etsy Data Scraping NEW Shein Data Scraping NEW DoorDash Scraping NEW Instacart Scraping NEWTesco Data Scraping NEW Sainsbury's Scraping NEW ASDA Data Scraping NEW Ocado Scraping NEW ASOS Data Scraping NEW Rightmove Scraping NEW Deliveroo Scraping NEW Zalando Scraping NEW Otto Scraping NEW Cdiscount Scraping NEW Carrefour Scraping NEW Allegro Scraping NEW Bol.com Scraping NEWFlipkart Data Scraping JioMart Data Scraping NEW BigBasket Scraping NEW Myntra Data Scraping NEW Nykaa Data Scraping NEW Blinkit Data Scraping Zepto Data Scraping Zomato Data Scraping Swiggy Data ScrapingNoon Data Scraping NEW Amazon.ae Scraping NEW Talabat Data Scraping NEW Careem Data Scraping NEW PropertyFinder Scraping NEW
Platforms by Region
🇺🇸 USA🇬🇧🇪🇺 UK/EU🇮🇳 India🇦🇪 ME🌏 SEA🌎 LATAM🇨🇳🇯🇵🇰🇷🇦🇺 AUAmazon Data Scraping #1 Walmart Data Scraping Target Data Scraping NEW Shopify Scraping HOT TikTok Shop Scraping HOT Costco Data Scraping NEW Best Buy Scraping NEW Home Depot Scraping NEW Etsy Data Scraping NEW Shein Data Scraping NEW DoorDash Scraping NEW Instacart Scraping NEWTesco Data Scraping NEW Sainsbury's Scraping NEW ASDA Data Scraping NEW Ocado Scraping NEW ASOS Data Scraping NEW Rightmove Scraping NEW Deliveroo Scraping NEW Zalando Scraping NEW Otto Scraping NEW Cdiscount Scraping NEW Carrefour Scraping NEW Allegro Scraping NEW Bol.com Scraping NEWFlipkart Data Scraping JioMart Data Scraping NEW BigBasket Scraping NEW Myntra Data Scraping NEW Nykaa Data Scraping NEW Blinkit Data Scraping Zepto Data Scraping Zomato Data Scraping Swiggy Data ScrapingNoon Data Scraping NEW Amazon.ae Scraping NEW Talabat Data Scraping NEW Careem Data Scraping NEW PropertyFinder Scraping NEW Pricing & Promotions
MAP Violations Brand Protection Counterfeit Detection Price Intelligence AI HOT Data Intelligence
Pricing & Promotions
MAP Violations Brand Protection Counterfeit Detection Price Intelligence AI HOT Data Intelligence Brand & Intelligence
Share of Search Content Audit & PDP Reviews & Ratings Retail Media Buy Box Monitoring Social Commerce HOT Live Commerce NEW Agentic Commerce NEW
Brand & Intelligence
Share of Search Content Audit & PDP Reviews & Ratings Retail Media Buy Box Monitoring Social Commerce HOT Live Commerce NEW Agentic Commerce NEW Digital Shelf & Search
Assortment Planning Competitive Benchmarking Product Availability Seller Intelligence NEW Q-Commerce NEW
Digital Shelf & Search
Assortment Planning Competitive Benchmarking Product Availability Seller Intelligence NEW Q-Commerce NEW AssortmentE-commerce Intelligence Hyperlocal Insights POI & Store Locator DTC Brand Analytics NEW
AssortmentE-commerce Intelligence Hyperlocal Insights POI & Store Locator DTC Brand Analytics NEW For Retailers
For Retailers Marketplace Scrapers
Amazon API TikTok Shop API HOT Uber Eats API Airbnb API Zepto / Blinkit API Instacart API NEW Talabat API NEW
Marketplace Scrapers
Amazon API TikTok Shop API HOT Uber Eats API Airbnb API Zepto / Blinkit API Instacart API NEW Talabat API NEW Data APIsWeb Extract API Reviews API SERP API Pricing Webhook NEW
Data APIsWeb Extract API Reviews API SERP API Pricing Webhook NEW Universal APIsLive Crawler API Scheduler Realtime Alerts Webhook Delivery 🐍 Python SDK 💚 Node.js SDK
Universal APIsLive Crawler API Scheduler Realtime Alerts Webhook Delivery 🐍 Python SDK 💚 Node.js SDK Delivery & SDKs
Delivery & SDKs Knowledge Center
Digital Shelf Playbook MAP Compliance Guide Pricing Intel Guide Scraping Compliance TikTok Shop Guide NEW Cross-Border Guide NEW
Knowledge Center
Digital Shelf Playbook MAP Compliance Guide Pricing Intel Guide Scraping Compliance TikTok Shop Guide NEW Cross-Border Guide NEW Guides & Playbooks
Sample Datasets HOT ROI Calculator NEW API Postman Collection Demo Dashboards Free API Playground NEW Press Kit
Guides & Playbooks
Sample Datasets HOT ROI Calculator NEW API Postman Collection Demo Dashboards Free API Playground NEW Press Kit Downloads & Tools
Trust Center About Us FAQs Careers
Downloads & Tools
Trust Center About Us FAQs Careers Trust & Company
Trust & Company E-commerce & Retail
E-commerce & Retail Grocery & FMCG
Grocery & FMCG Travel & Hospitality
Travel & Hospitality Food & Restaurants
Food & Restaurants Finance & Legal
Finance & Legal Healthcare & Pharma
Healthcare & Pharma Real Estate & Local
Real Estate & Local Automotive & Mobility
Automotive & Mobility Media & Entertainment
Media & Entertainment Emerging Industries
Emerging Industries














































