Actowiz Metrics Real-time  analytics dashboard for brands! Try Free Demo
analytics dashboard for brands! Try Free Demo
Scalable web, app & AI-powered extraction. 99.9% accuracy.
All Services → Core Scraping Services
Core Scraping Services
 Top Global Platforms
Top Global Platforms
 Platforms by Region
Platforms by Region
🇦🇪 Expanding across UAE, Saudi, Qatar, Kuwait & more
Request Custom Platform →🌏 Singapore, Indonesia, Thailand, Philippines, Vietnam & Malaysia
Request Custom Platform →🌎 Brazil, Mexico, Argentina, Colombia & Chile
Request Custom Platform → Pricing & Promotions
Pricing & Promotions
 Brand & Intelligence
Brand & Intelligence
 Digital Shelf & Search
Digital Shelf & Search
 Assortment
Assortment For Retailers
For RetailersWhich solution fits?
Talk to Expert Marketplace Scrapers
Marketplace Scrapers
 Data APIs
Data APIs Universal APIs
Universal APIs Delivery & SDKs
Delivery & SDKsReady to integrate?
Start Free Trial Knowledge Center
Knowledge Center
 Guides & Playbooks
Guides & Playbooks
 Downloads & Tools
Downloads & Tools
 Trust & Company
Trust & CompanyScalable web, app & AI-powered extraction. 99.9% accuracy.
All Services → Core Scraping Services
Top Global Platforms
Pricing & Promotions
Brand & Intelligence
Digital Shelf & Search
Assortment For RetailersWhich solution fits?
Talk to Expert Marketplace Scrapers
Data APIs Universal APIs Delivery & SDKsReady to integrate?
Start Free Trial Knowledge Center
Guides & Playbooks
Downloads & Tools
Trust & Company
In today’s digital world, data is the new currency. Businesses, researchers, and individuals alike are increasingly reliant on web data to make informed decisions. However, manually collecting data from websites can be a tedious and time-consuming task. Enter web page scrapers—powerful tools that automate the process of online data extraction, making it more efficient and accessible even to beginners. In this guide, we’ll explore the fundamentals of web page scrapers, delve into advanced web scraping techniques, and offer insights into optimizing your scraping processes.
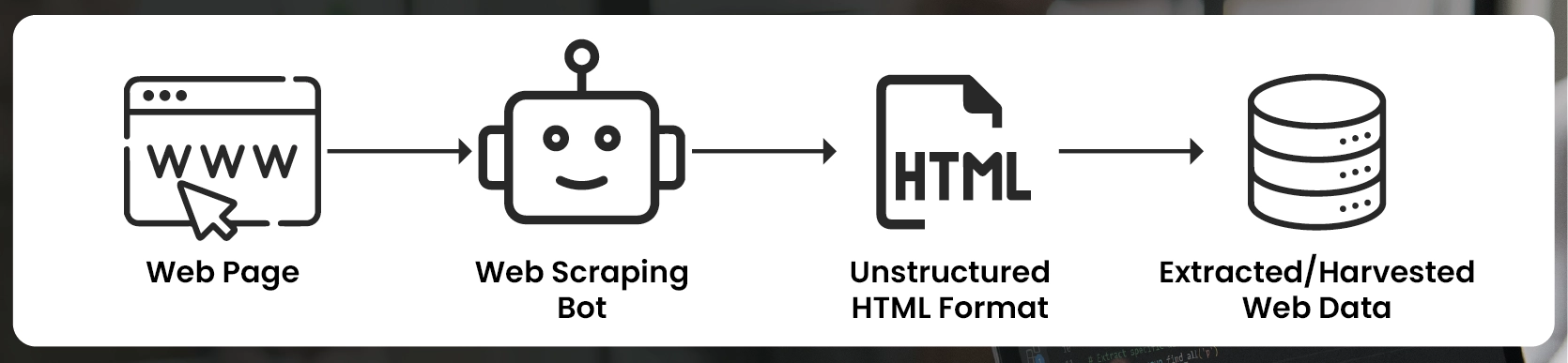
Web page scrapers are software tools designed to automatically extract data from websites. By simulating human browsing behavior, these tools navigate through web pages, identify specific content, and collect it for further analysis. Whether you’re scraping online data for competitive analysis, market research, or academic purposes, web scrapers are invaluable in extracting vast amounts of data quickly and accurately.
At the core, a web scraper sends HTTP requests to a website’s server, retrieves the HTML content, and then parses the HTML to extract the desired data. Advanced web scraping techniques may also involve handling dynamic content, JavaScript rendering, and API interaction. The extracted data can then be stored in various formats, such as CSV, JSON, or directly into a database, making it easy to analyze and utilize.
Setting up a web scraper might seem challenging for beginners, but with the right tools and guidance, it becomes a manageable task. Here’s a step-by-step guide to help you begin your web scraping journey:
The first step in any web scraping project is identifying the website you wish to scrape. Ensure that scraping the site is legal and adheres to the website’s terms of service. Some websites may have restrictions in their robots.txt file, which outlines what parts of the site can be accessed by web crawlers.
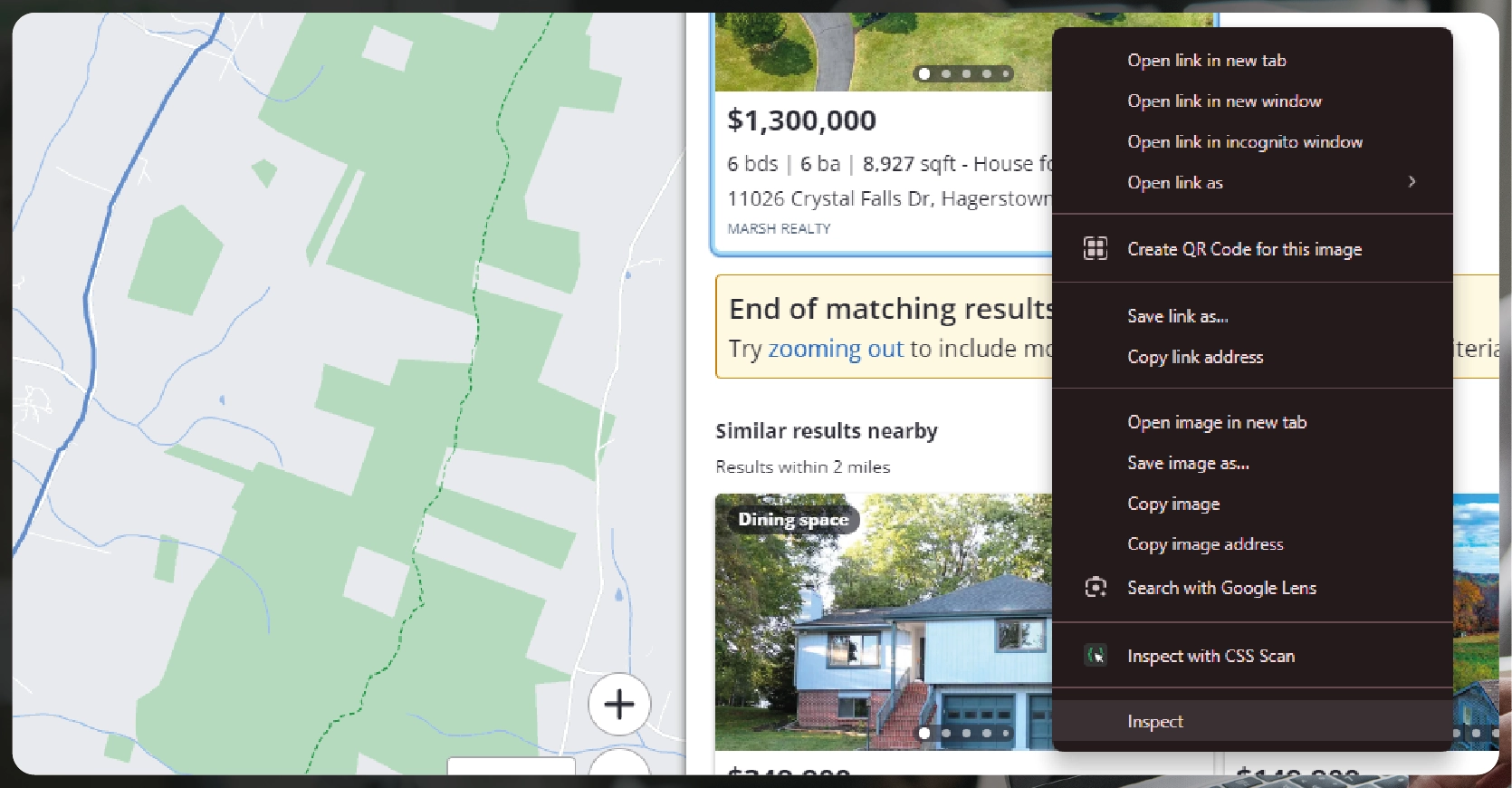
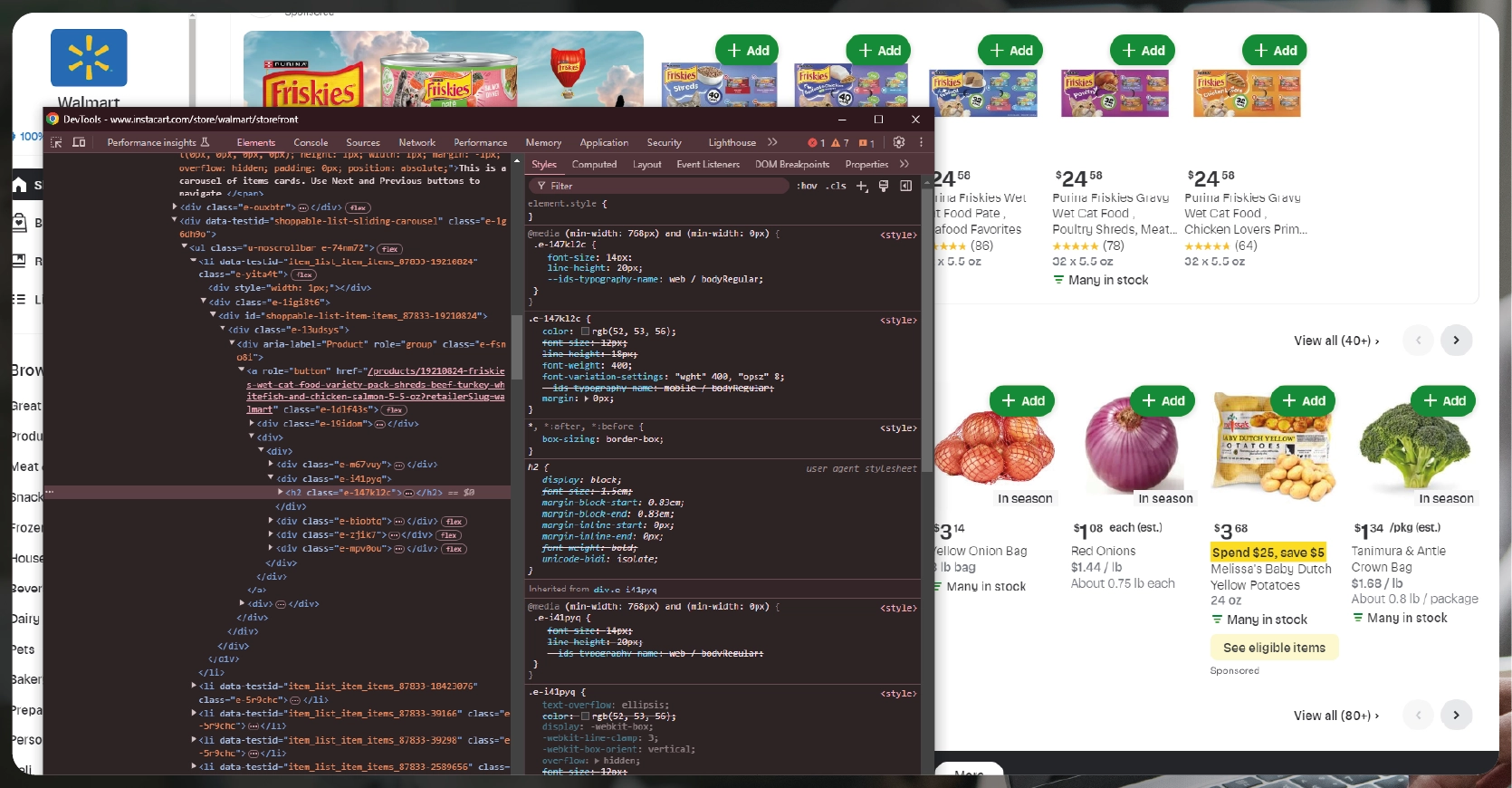
Before diving into web scraping, it's essential to grasp the structure of the web page. Utilize your browser's developer tools to examine the CSS, HTML selectors, and JavaScript elements. This inspection will guide you in pinpointing the exact data points you aim to extract.

For beginners, selecting an easy-to-use web scraping tool is key. Instant Data Scraper is a popular choice for those new to web scraping. It’s a browser extension that allows you to scrape data from websites with minimal setup. For more advanced users, tools like BeautifulSoup and Scrapy (both Python-based) offer greater flexibility and control over the scraping process.
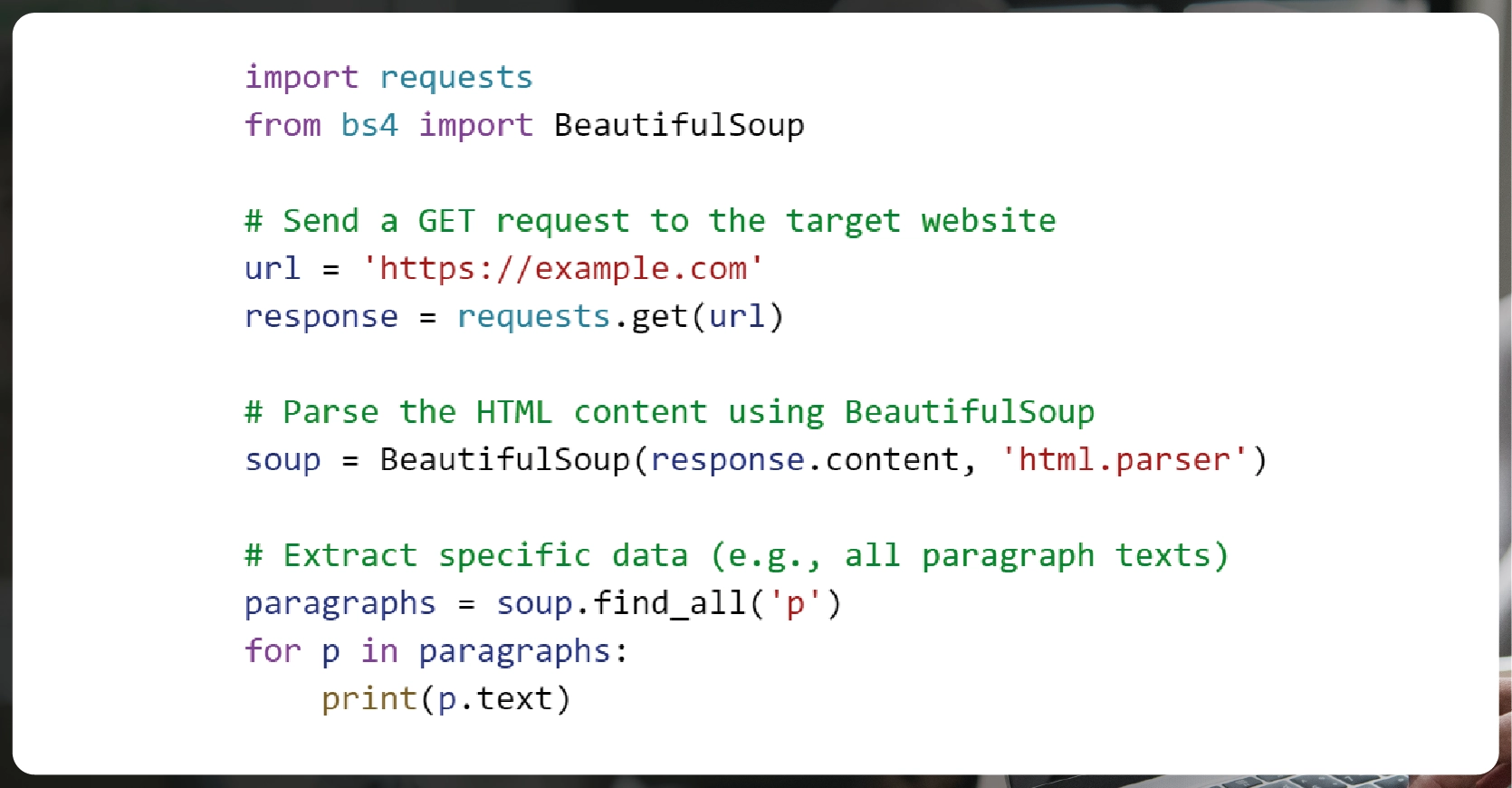
If you’re using a programming language like Python, you’ll need to write a script that sends requests to the website, retrieves the data, and parses it. For instance, with BeautifulSoup, you can easily extract data by navigating through the HTML tags and attributes.
Here’s a simple example using Python and BeautifulSoup:

Once you’ve extracted the data, you’ll need to save it in a structured format. Common formats include CSV, JSON, and databases like MySQL or MongoDB. This step is crucial for organizing and analyzing your data effectively.

Web scraping isn’t always smooth sailing. You may encounter issues like request failures, changes in website structure, or blocked IP addresses. Implement error handling in your script to manage these challenges. For instance, use try-except blocks in Python to catch exceptions and ensure your script continues running.
Always respect the website’s robots.txt file and be mindful of the site’s request rate limits. Overloading a server with too many requests in a short time can lead to your IP being blocked. Implement throttling mechanisms in your script to control the frequency of requests.
As you become more comfortable with basic web scraping, you may want to explore advanced techniques to enhance your data extraction capabilities. These techniques are especially useful for dealing with dynamic content, large-scale scraping, and scraping websites that implement anti-scraping measures.
Many modern websites use JavaScript to load content dynamically, which can pose challenges for traditional HTML parsers. Tools like Selenium or Playwright can be used to automate a browser, allowing you to scrape content that only appears after certain user interactions or JavaScript execution.
Some websites provide APIs (Application Programming Interfaces) that allow you to access their data directly, often in a more structured and reliable format than scraping the HTML. Understanding how to send API requests and parse the returned data can significantly streamline your scraping process.
Websites may block your IP if they detect too many requests coming from it in a short time. Using proxies can help you distribute your requests across multiple IP addresses, reducing the risk of being blocked.
Automation is crucial when scraping large volumes of data. You can plan your scripts to run at regular intervals using tools like Unix-based system or Cron or Task Scheduler using Windows. To further enhance efficiency, leverage parallel processing techniques to run multiple scrapers simultaneously, significantly speeding up data extraction.

Web scraper optimization is crucial for ensuring that your scraping activities are efficient, reliable, and scalable. Here are some tips to optimize your web scraping setup:
Efficient code is the backbone of any successful web scraping project. Optimize your script by minimizing the number of requests, reducing unnecessary data processing, and using libraries that are designed for speed and performance.
If you’re scraping the same pages multiple times, consider implementing caching to avoid sending repetitive requests to the server. Caching can save bandwidth, reduce server load, and speed up your scraping process.
When scraping large datasets, you might encounter duplicate data. Implement deduplication techniques to ensure that your final dataset is clean and free of redundancies.
Websites change frequently, and your scraping scripts may break if the site’s structure is updated. Regularly monitor your scripts and update them as needed to maintain data accuracy.
Headless browsers allow you to automate web scraping without a graphical interface, making the process faster and more resource- efficient. Tools like Headless Chrome or PhantomJS are popular choices for this purpose.
Web scraping has a wide range of applications in various industries, from e-commerce to finance. Businesses leverage web data extraction tools to gain insights, optimize pricing strategies, and stay ahead of the competition.
Web scraping allows businesses to monitor competitors’ websites for changes in product offerings, pricing, and customer feedback. This data is invaluable for making informed strategic decisions.
For companies offering pricing strategy consulting services, web scraping is essential for collecting and analyzing competitor pricing data. This information helps in developing price optimization strategies and understanding market trends.
Web scraping is a key component of price intelligence AI systems. By continuously monitoring market prices, businesses can optimize their pricing strategies in real-time to maximize revenue and maintain a competitive edge.
Web scraping enables companies to gather large amounts of data on market trends, consumer behavior, and industry developments. This data-driven approach allows businesses to make strategic decisions based on real-time insights.
While web scraping offers numerous benefits, it’s important to approach it with ethical considerations in mind. Always respect the website’s terms of service and privacy policies. Scraping data that is protected by copyright or other legal restrictions can lead to legal repercussions. Additionally, consider the impact of your scraping activities on the website’s performance. High-frequency scraping can put a strain on servers, leading to potential downtime or service disruptions for other users.
Web page scrapers are powerful tools that unlock a wealth of data from the web. By mastering web scraping tools and techniques, you can efficiently extract valuable information for business intelligence, market research, and beyond.
Whether you’re a beginner just starting with tools like Instant Data Scraper or an advanced user looking to optimize your scraping processes, this guide provides a comprehensive overview of how to harness the power of web scrapers effectively.
As you continue to develop your skills in web scraper development and online data extraction, remember to stay informed about the ethical and legal aspects of scraping, ensuring that your activities are both responsible and compliant.
For businesses looking to integrate web scraping into their operations, partnering with a data extraction company or consulting firm can provide additional expertise and resources to maximize the benefits of web scraping. With the right approach, web scraping can be a game- changer for gaining insights, optimizing prices, and staying competitive in today’s data-driven world.
Ready to unlock the potential of web scraping? Partner with Actowiz Solutions today and take your data extraction efforts to the next level! You can also reach us for all your mobile app scraping, web scraping, data collection, and instant data scraper service requirements!
Our web scraping expertise is relied on by 4,000+ global enterprises including Zomato, Tata Consumer, Subway, and Expedia — helping them turn web data into growth.
Watch how businesses like yours are using Actowiz data to drive growth.
From Zomato to Expedia — see why global leaders trust us with their data.
Backed by automation, data volume, and enterprise-grade scale — we help businesses from startups to Fortune 500s extract competitive insights across the USA, UK, UAE, and beyond.






We partner with agencies, system integrators, and technology platforms to deliver end-to-end solutions across the retail and digital shelf ecosystem.







Scrape Weekly MSC Itinerary and Pricing Data for cruise fare tracking, itinerary monitoring, route analytics, and travel market intelligence.

Buc-ee's locations data scraping in the USA in 2026 helps brands unlock location insights, optimize expansion strategies, and gain a competitive edge.

Mother's Day 2025 E-commerce Insights report — 47,000+ SKUs across 12 platforms. Pricing, discounts, stock-outs & what brands should expect in 2026.
Whether you're a startup or a Fortune 500 — we have the right plan for your data needs.



 E-commerce & Retail
E-commerce & Retail Grocery & FMCG
Grocery & FMCG Travel & Hospitality
Travel & Hospitality Food & Restaurants
Food & Restaurants Finance & Legal
Finance & Legal Healthcare & Pharma
Healthcare & Pharma Real Estate & Local
Real Estate & Local Automotive & Mobility
Automotive & Mobility Media & Entertainment
Media & Entertainment Emerging Industries
Emerging Industries




























