What does a new judgment of hiQ Labs vs. LinkedIn Corp mean for data scraping? We have studied the latest developments and explained the present legal status of data scraping.
A new verdict in the case of HiQ Labs vs. LinkedIn Corp occurred lately. What does that mean for data scraping? How does that relate to the last judgment of the US Ninth Circuit Court of Appeals, which affirmed the authority of public web scraping?
LinkedIn represents a new judgment like a “big win […] confirming LinkedIn’s legal situations against him for the last six years”. With this statement, one might get the impression that LinkedIn has won the entire dispute and its proceedings ended, or the past judgment where hiQ won got overruled. But let's not get deceived. It is a fact that LinkedIn prevailed in most of the claims, which were subject to any particular decision. Though the decision wasn’t as final as it not, all the claims had been decided, and the last example was not domineered.
The significant thing about highlighting is that a new judgment hasn’t replaced the previous ones. As an alternative, every decision decides various legal questions.
The Ninth Circuit's Opinion - April 18, 2022
This decision created a vital example by confirming that one can’t be illegitimately liable for extracting publicly accessible data.
Before the decision had made that clear, it utilized to be a general claim that data scraping violates the CFAA (Computer Fraud and Abuse Act), an anti-hacking act that criminalizes retrieving protected computers without authorization to do so. This court held as this concept doesn’t apply to accessing public sites. It mentioned that defining feature of general sites is the lack of access limitations. So, accessing publicly accessible data can’t be unauthorized, as per the CFAA correct reading.
Procedurally, in the case of hiQ v LinkedIn, the court had decided on hiQ’s motion for any preliminary injunction.
Judgment of the District Court - October 27, 2022

As per the new verdict, the court decided on many claims made by parties, mainly about contractual obligations.
The court apprehended that the agreement between LinkedIn and hiQ prohibiting extracting and making fake accounts was broken by hiQ. The costs and other associated legal questions persist undecided and await more proceedings. The court has also determined that LinkedIn's actions that severely damaged client relationships of hiQ and eventually squashed their business were not illegal, as LinkedIn took all the steps to shield its rights until litigation. The court made another decision to give sanctions for not showing evidence as per the law.
The effect on data scraping
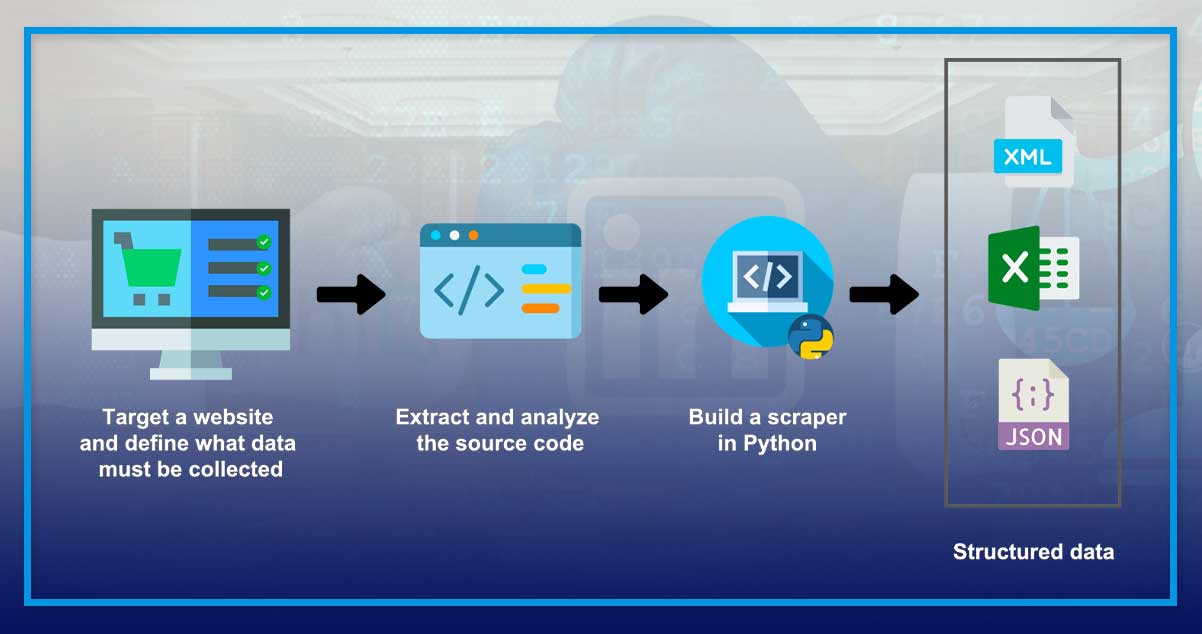
It is not valuable to analyze the contractual language information and factual distinctions resulting in the contract breach. However, it is an excellent reminder that when practically scraping, you have to think about if you have the contract placed. That often occurs whenever you sign in to the website and are asked to read and accept a site's terms & conditions. These terms may include limitations or prohibiting data scraping overall. Always be more careful while you extract data behind the login.
Conclusion
We can see that web scraping Services law is slowly emerging and is definitely required. However, it is a pity that in a predetermined area of data scraping proscriptions in terms of usage and careful denial of accessing public sites for competitors, the courts tend to limit the analysis to a language of contract provisions. This will become worth considering if it is legal and legitimate to selectively stop some from using public platforms accessible to all.








