The internet is flooded with innumerable information relating to how to scrape data. But hardly any information is available on how to scrape TV show episodes for IMDb ratings. If you are the one looking for the same, then you are at the right place. This blog will give you stepwise information on the scraping procedure.
Let’s scrape the IMDb movie ratings along with their details using Python’s BeautifulSoup library.
Modules Required:
Below is the module list needed to scrape from IMDB
- 1. Requests: This library is an essential part of Python. It makes HTTP requests to a specified URL.
- 2. Bs4: This object is provided by Beautiful Soup. It is a web scraping framework for Python.
- 3. Pandas: This library is made over the NumPy library, providing multiple data structures and operators to alter numerical data.
Approach:
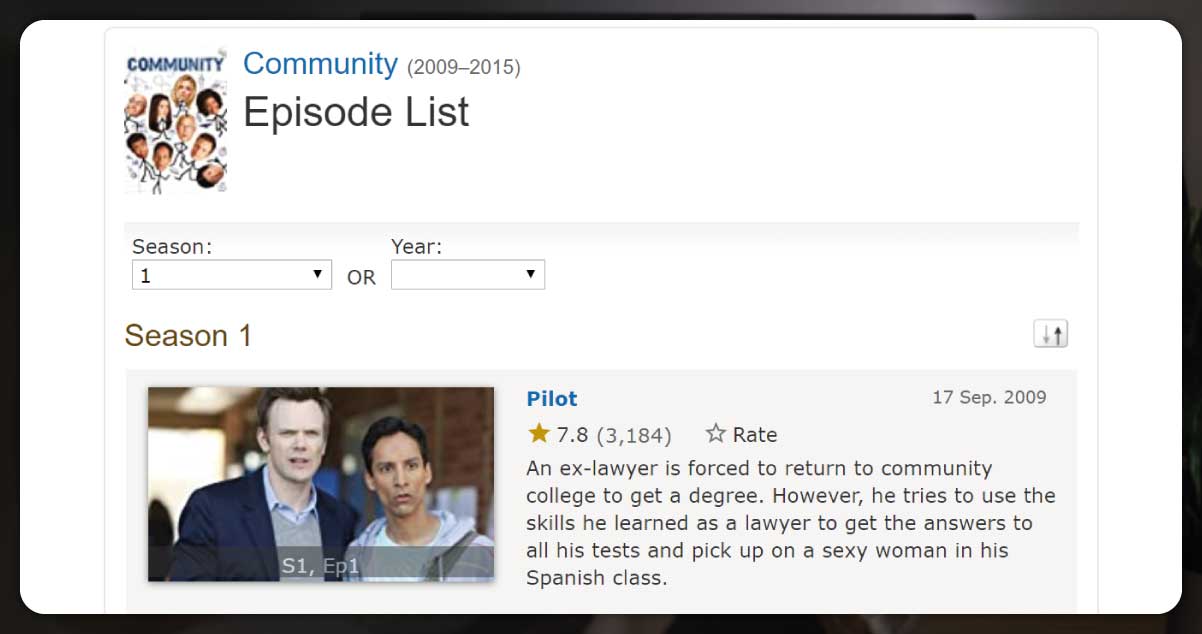
First, navigate through the season 1-page series. It will comprise the list of season episodes. Series 1 will appear like this:
Now, get the page URL. It will appear like this.

http://www.imdb.com/title/tt1439629/episodes?season=1
‘tt1439629’ is the show’s ID. If you aren’t using Community, then this id will be different.
Next, to request content from the web server, we will use get(). We will then store the server response in the variable response. Then, we will check for a few lines. Within the response lies the webpage’s HTML code.

Parse HTML Content Using BeautifulSoup

Create a BeautifulSoup object to parse the response.text. Now, assign this object to html_soup. The html.parser argument signifies that we will perform parsing with the help of Python’s built-in HTML parser.
The variables that we obtain here are
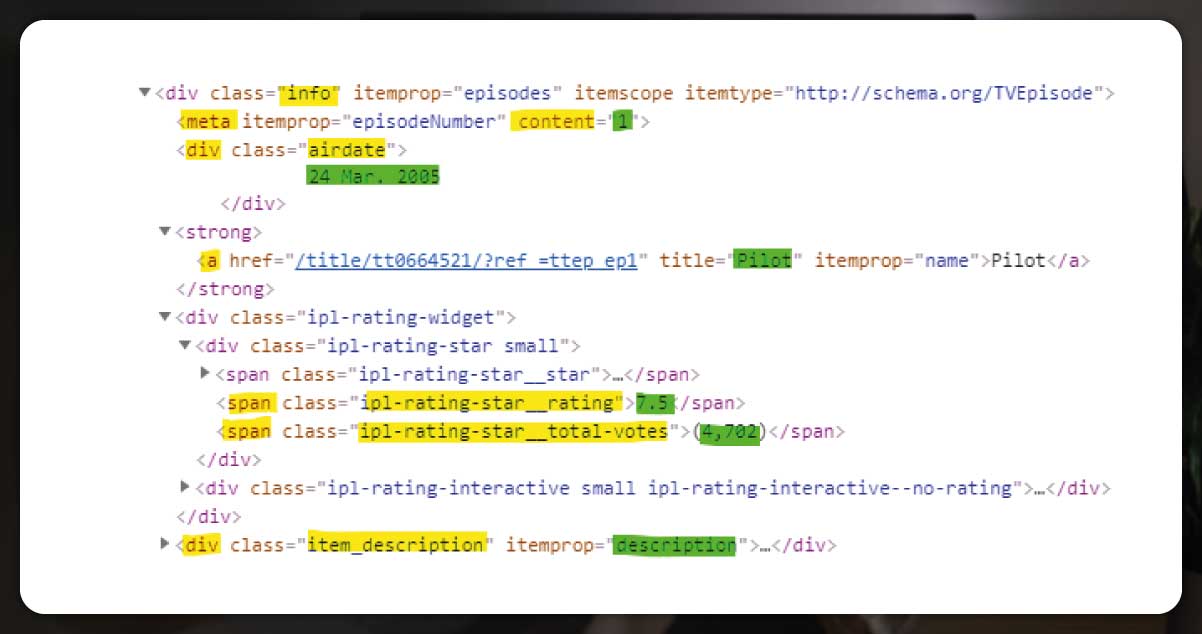
- Episode Number
- Episode Title
- IMDb Rating
- Airdate
- Episode Description
- Total Votes
In the above image, if you notice attentively, you will find that the information that we require is in <div class="info" ...> </div>
The yellow part contains tags of the code. At the same time, the green ones are the data that we are trying to extract.
Now, from the page, capture all the instances of <div class="info" ...> </div>

find_all will return a ResultSet object which comprises a list of 25
<div class="info" ...> </div>
Extraction of Required Variables
Now, we will extract the data from episode_containers for an individual episode.
Episode Title

For the title, we require a title attribute from < a > tag.
Episode Number

It lies within the meta tag under the content attribute.
Airdate

It lies within the < div > tag with the class airdate. If we stripe to remove whitespace, we can easily obtain test attributes.
IMDb Rating

It lies within the < div > tag with the class ipl-rating-star__rating. It also uses text attributes.
Total Votes

It includes the same tag. The only difference is that it lies within different classes.
Episode Description

Here we will perform the same thing as we did for the airdate but only will change the class.
Putting Final Code Altogether

Repeat the same for each episode and season. It will require two ‘for’ loops. For per season loop, adjust the range() based on the season numbers you want to scrape.
Cleaning of Data


Total Votes Count Conversion to Numeric
To make a function numeric, we will use replace() to remove the ‘,’ , ‘(‘, and ‘)’ from total_votes
Apply the function and change the type to int using astype()
Convert airdate from String to Date Time

Now the available data is ready for analysis.

Ensure to save it
CTA: For more information, contact Actowiz Solutions now! You can also reach us for all your mobile app scraping and web scraping services requirements.











