
If you're looking for new apartments and wish to see the properties are accessible, there are good chances you've searched for them. However, if you find what looks like a dream home for you, what if you'd love to see more information about that?

And that's when you need web scraping services. Web extraction is the procedure for scraping data from different websites and converting it into JSON or CSV files. You can use it for other objectives like analyzing various market conditions, knowing which apartments are accessible at different price points, etc.
In this blog, we have discussed how to extract data from real estate websites. The objective is to scrape real estate data from Amsterdam with the help of Python.
In this tutorial, we used Python to scrape data. We initially import BeautifulSoup, writer, requests, and time modules with an element tree. These are all required packages to scrape data from the HTML page.
We initially imported BeautifulSoup. This is the Python package, which takes data from XML and HTML documents.
All the data scraping companies utilize requests either as it is or creates request handlers for requests. The initial step is to ping the website data and make the requests. For that, we have the 'Requests' module. This module is the 'ruler' of all Python modules.
We must write that in the CSV file when the data is attained. It can be done with a writer module. Another popular option is Pandas to achieve similar goals, but we will write packages.
After getting data, we have to execute it for smaller periods between requests. If we load the targeted website using recommendations - its server will get overloaded, resulting in a service shutdown. As an accountable web extraction service - we have to avoid that. And that's why we want a few time gaps between every HTTP request.

Lastly, we want a random module for generating an unexpected time to halt execution and an element tree to find the XPath. In case a gap between requests is comparable, it might be used to identify a web scraper. Therefore, we make that random with an unexpected Python package.
A lot of sites dislike data scrapers to scrape the data. They stop requests which come in with no good browser like a User-Agent. Therefore, we use headers for adding user agents to requests. These requests carry a user agent with different request headers, like a payload for the server. Here, only a user agent deals.

The
base_url is to get a page_url of every page on a website. pages_url=[] is the empty listing to store all links to every page. listing _url[] is an open listing to keep a link to every apartment on every page.
We require URLs for each page and we understand that there is total 22 pages on this site. Therefore, we make a for loop to get every page_url through concatenating numbers from 1-22 like strings. We save each of those pages in a list pages_url.

The get_dom() technique is to have a dom from a URL. We convey the_url like an argument. Then, we store requests from a URL in reply. We make the soup variable and create a dom with the soup. This technique returns a dom.

The get_listing_url() technique is used to retrieve a listing_url to every apartment information.

We get a dom from get_dom() technique by passing a page_url of every page. With the XPath
To find the xpath, we need to study the element and press Ctrl + F keys. Now, we specify a tag and a class name. In case we need a text, we have to stipulate text(), and in case we want a link, we have to stipulate @href.
We’ll have a link for every apartment's data. These saved links get stored in the list page_link_list[]. Then, we focus “https://www.pararius.com” using a page_link in a page_link_list and add all the links to a listing_url.

For every page_url in a list pages_url, we get the get_listing_url in every page through passing page_url like an argument. Also, we call a sleep method to halt some casual time to execute a code.
The attributes with their xpaths used are given below.
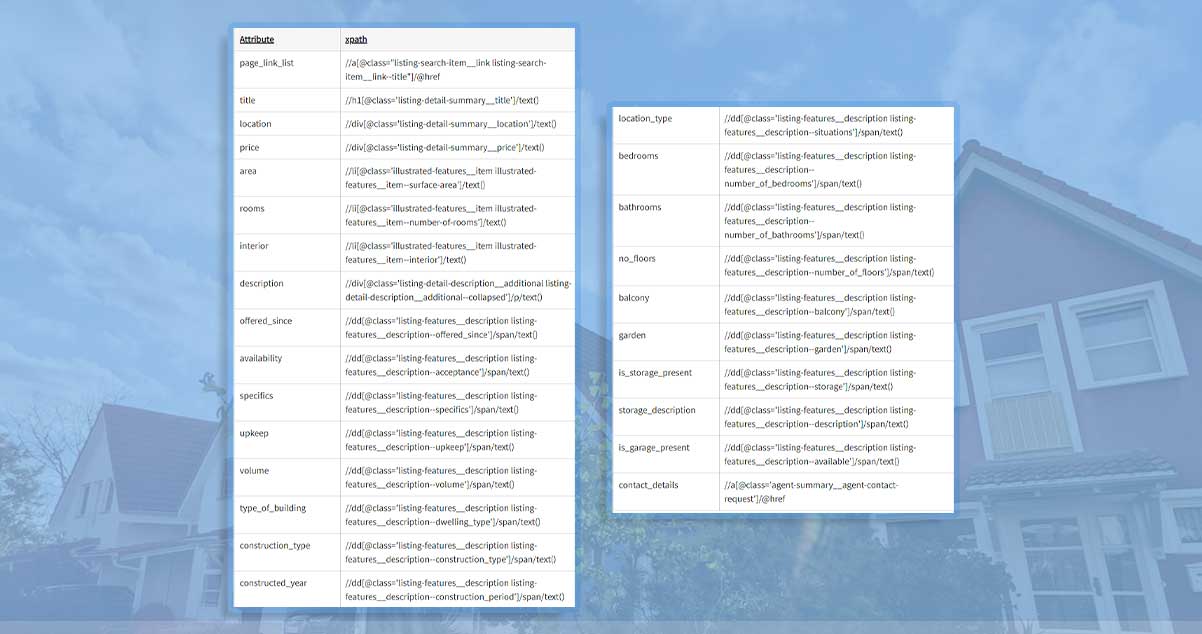

[Take them from the link given below and show them in an image]
https://www.blog.datahut.co/post/scraping-property-data
We open a file apartments.csv in writing modes as f. We utilize thewriter for writing data in a file. so, we make a listing heading to save the headings of every data and write its first row.

We have a listing_dom for every list_url from a listing_url through calling a get_dom() technique and pass list_url like an argument. We have a title of apartment calling a get_title() technique and a location through calling a get_location() technique.

The get_title() technique has a dom-like argument. We utilize try-except blocks to fetch data properly. In a try block, we save a title with XPath. We understand that XPath provides us with a data list but what we want is just the first element of this list. So, we have used [0] indexing and sliced a string title from the 10th character to the 14th, the last character of this string.
We also get an except block to facilitate the title that we couldn't scrape using XPath could be stored like "Title not accessible." We send a string title.
Likewise, we get the given methods, where XPath to those details vary from each other:
In a file writer, we got the variable list to get written on the CSV file. The listing contains:

- list_url
- title
- location
- price
- area
- rooms
- interior
- description
- offer
- specification
- upkeep_status
- volume
- type
- construction_type
- contruction_year
- location_type
- bedrooms
- bathrooms
- floors
- balcony_details
- garden_details
- storage_details
- storage_description
- garage
- contact
We write information of all buildings into a CSV file. The Python notebook with a CSV file attained are provided here.
Conclusion
We hope that you've liked this tutorial. Looking for a dependable data scraping solution and mobile app scraping services for all your data requirements? Contact Actowiz Solutions now!








