
Netflix is an OTT platform where it’s easy to watch unlimited movies and Shows. You can extract Netflix data to collect all episode names, ratings, cast, plan pricing, similar shows, etc. With this data, it’s easy to analyze what the users watch these days, and it will help in sentiment analysis.
We will use Python here to scrape Netflix data. We assume that you have installed Python on your PC. Let’s start with data scraping now!
Scrape Netflix Data
To start here, we will make a folder to install the different libraries we need during this tutorial.
Here, we will install a couple of libraries
1. Requests will assist us in making an HTTP connection using Netflix.
2. BeautifulSoup will assist us in making an HTML tree to get smooth data scraping.

We will extract Netflix page data. Within this folder, it’s easy to make a Python file where we would write the code. Our interest would be:



- Name of show
- Total seasons
- Subject
- Episode Names
- Genre
- Episode Overview
- Category
- Cast
- Social media links
We understand this is a longer data list; however, in the end, you will get a readymade code to scrape Netflix data for any page.
Let’s find the locations of all these elements

The title gets stored under the h1 tag of a class title-title.

Total seasons get stored under the span tag in a duration class.
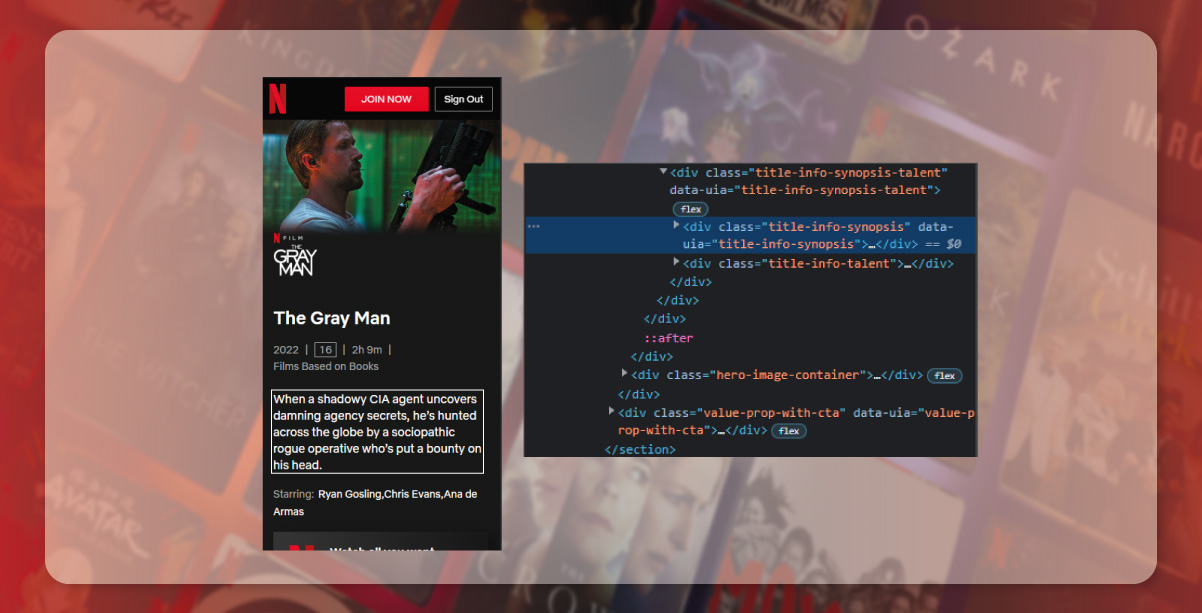
The about segment gets stored under the div tag in a class hook-text.
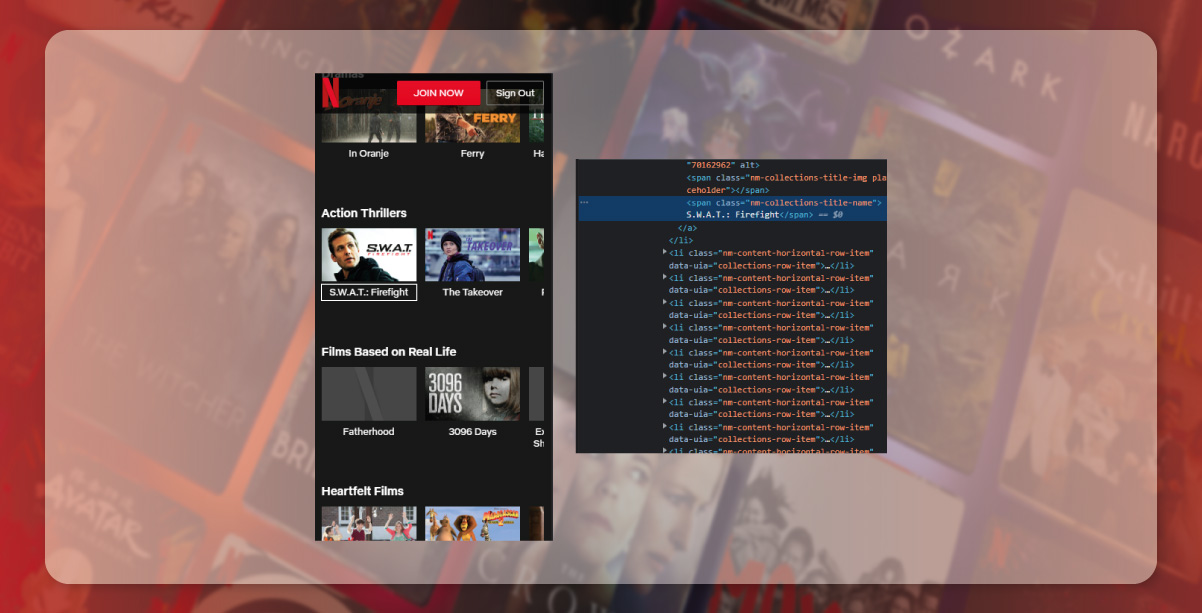
The episode’s title gets stored under the p tag having class episode-synopsis.

Genre gets stored under the span tag having class item-genres.

The show category data gets stored under the span tag having a class item-mood-tag.
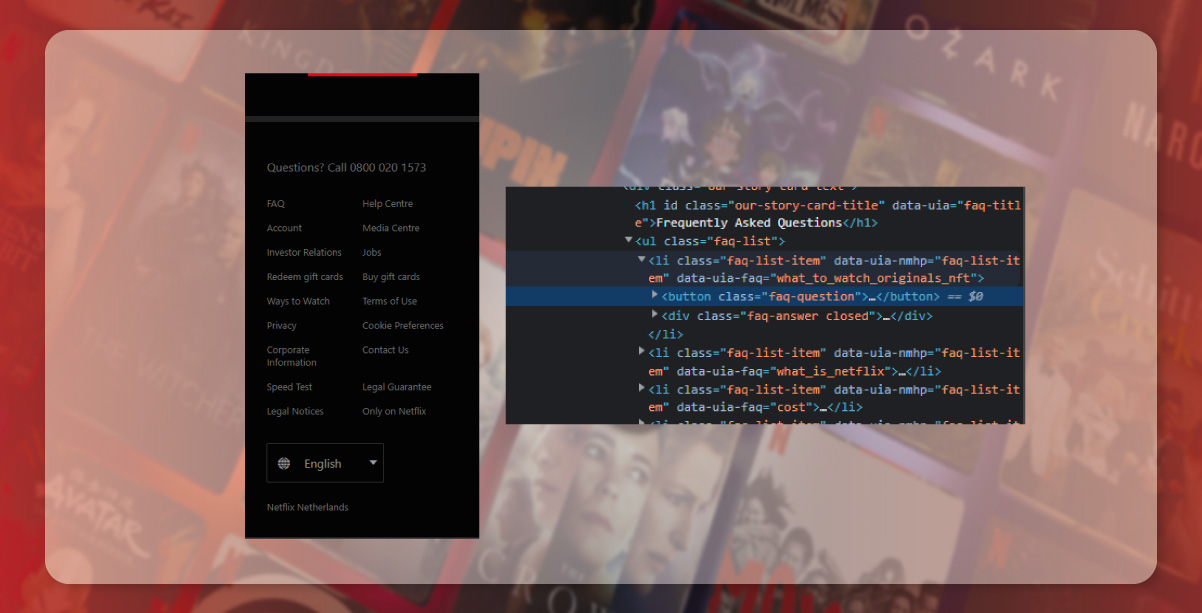
Social Media links could be available under the tag having a class name called social-link.
The cast gets stored under the span tag having class item-cast.
Let’s begin with making the regular GET requests to the targeted webpage and observe what happens.

If you find 200, then you have successfully extracted our targeted page. Now, let’s scrape details from this data with BeautifulSoup.

Let us initially scrape all data properties in sequence. As discussed here, we would be using similar HTML locations.

Now, let’s scrape the episode data.

The whole data is within ol tag. Therefore, we initially get the ol tag and all li tags within it. After that, we utilized a loop to scrape title & description data.
Now, let’s scrape the genre data.
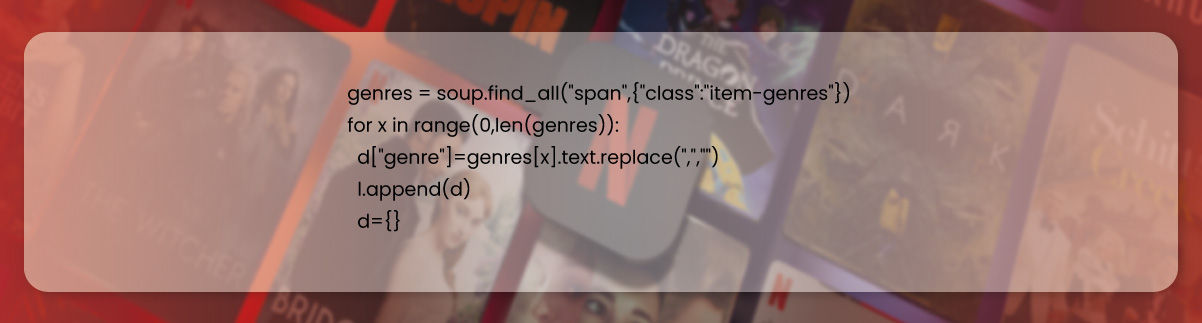
The genre could be available under the class item-genre. Here, we have utilized a loop to scrape all genres.
Let’s scrape the rest of the data properties having similar techniques.


We have succeeded in extracting all data from Netflix.
Complete Code

Using this code, we have extracted Name, Seasons name, Subject, Genre, Mood, Cast, Social links, etc. By making some changes in this code, you can scrape data from Netflix.
Conclusion
You can utilize Web Scraping API for scraping data from Netflix without being blocked. This is a fast way to scrape complete Netflix pages. By changing a show title ID you can extract nearly all shows from Netflix. You need to get IDs of these shows. Instead of BS4, you can use Xpath for creating HTML tree for web scraping services.
We hope you have liked this small tutorial about scraping Netflix data. Let us know if you want any help with your web extraction and Mobile App Scraping Services demands.








